
AI 教程:使用 Mov2mov 生成视频
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。

ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。

这一篇内容我们就来介绍一些使用微调模型控制生成画风的案例。
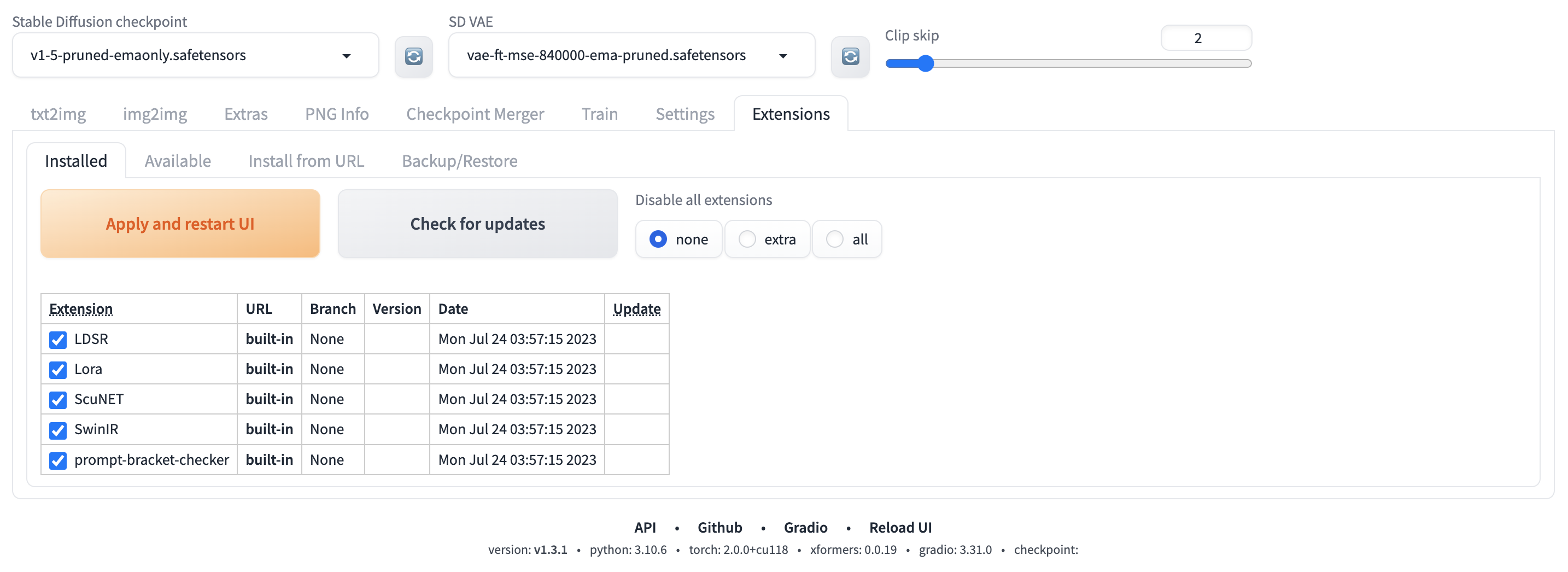
这里我们就来讲一讲如何在 Stable Diffusion WebUI 中配置各种扩展。

我们可以使用很多其他的模型来进行不同细分方向的 AI 绘画,我们这篇内容就来介绍一下这些模型的区别,以及如何在 WebUI 中使用它们。

Stable Diffusion WebUI 提供了多种批量生成图像的功能,可以帮助我们更加高效地完成大量的绘图任务。
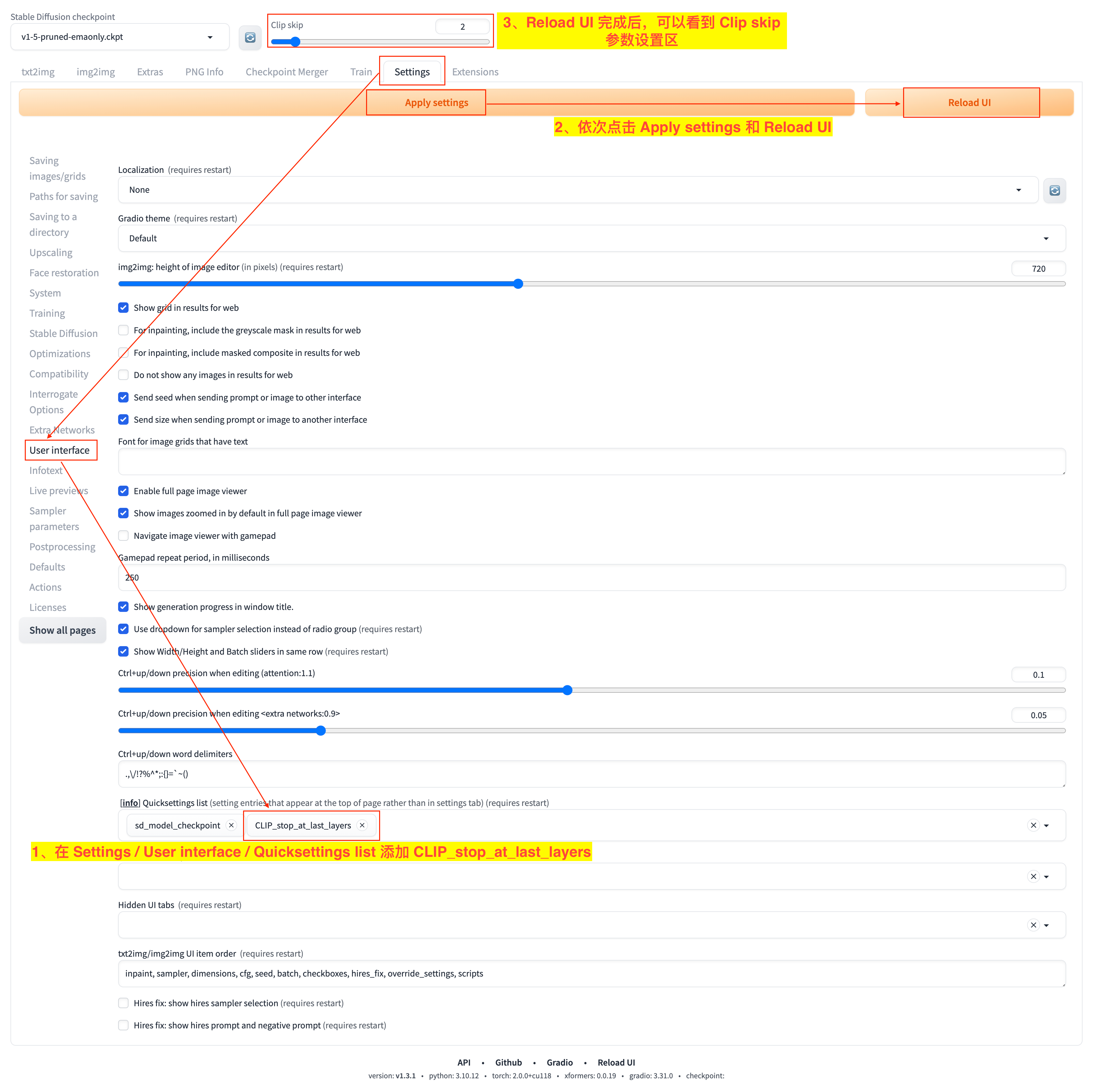
CLIP(Contrastive Language-Image Pre-training)是用于将提示词文本转换为数字表示的神经网络模型。
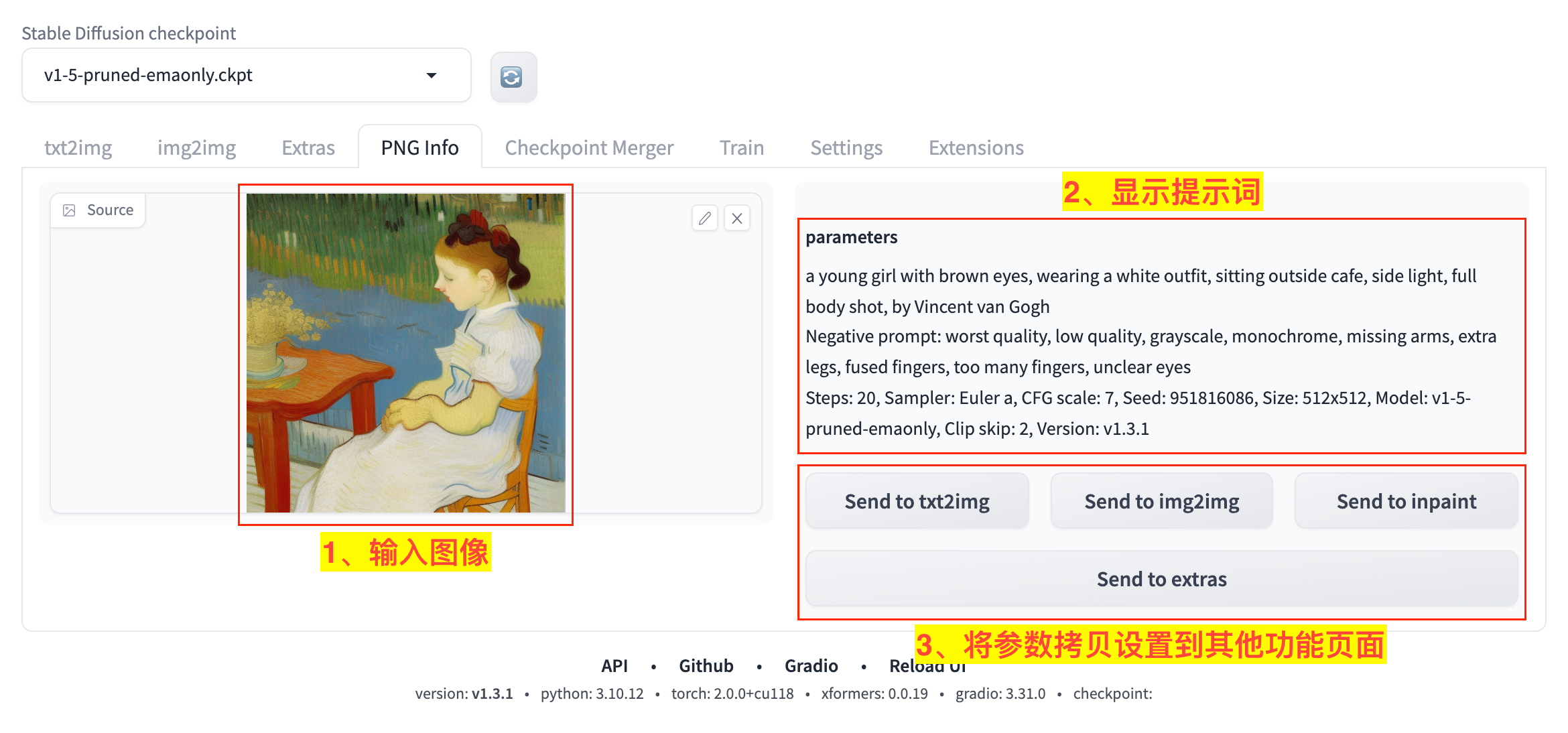
有时候我们看到不错的 AI 生成作品,想要获得对应的提示词来自己生成类似的图片,这时候有什么办法吗?

Stable Diffusion WebUI 为我们提供了其他方式来生成高分辨率的高清图,我们里就来介绍一下这些方案。

Stable Diffusion 除了完整的绘制一幅图像,还能对图像的部分区域做重绘。

Stable Diffusion 除了支持完全通过提示词来生成图像外,还可以支持使用图像加提示词共同引导来生成图像的能力。

这篇内容就来讨论一下 Stable Diffusion WebUI 提示词技巧。

Stable Diffusion 作为一款文本生成图像的 AI 绘画工具,其最核心的能力就是『文生图(txt2img)』。
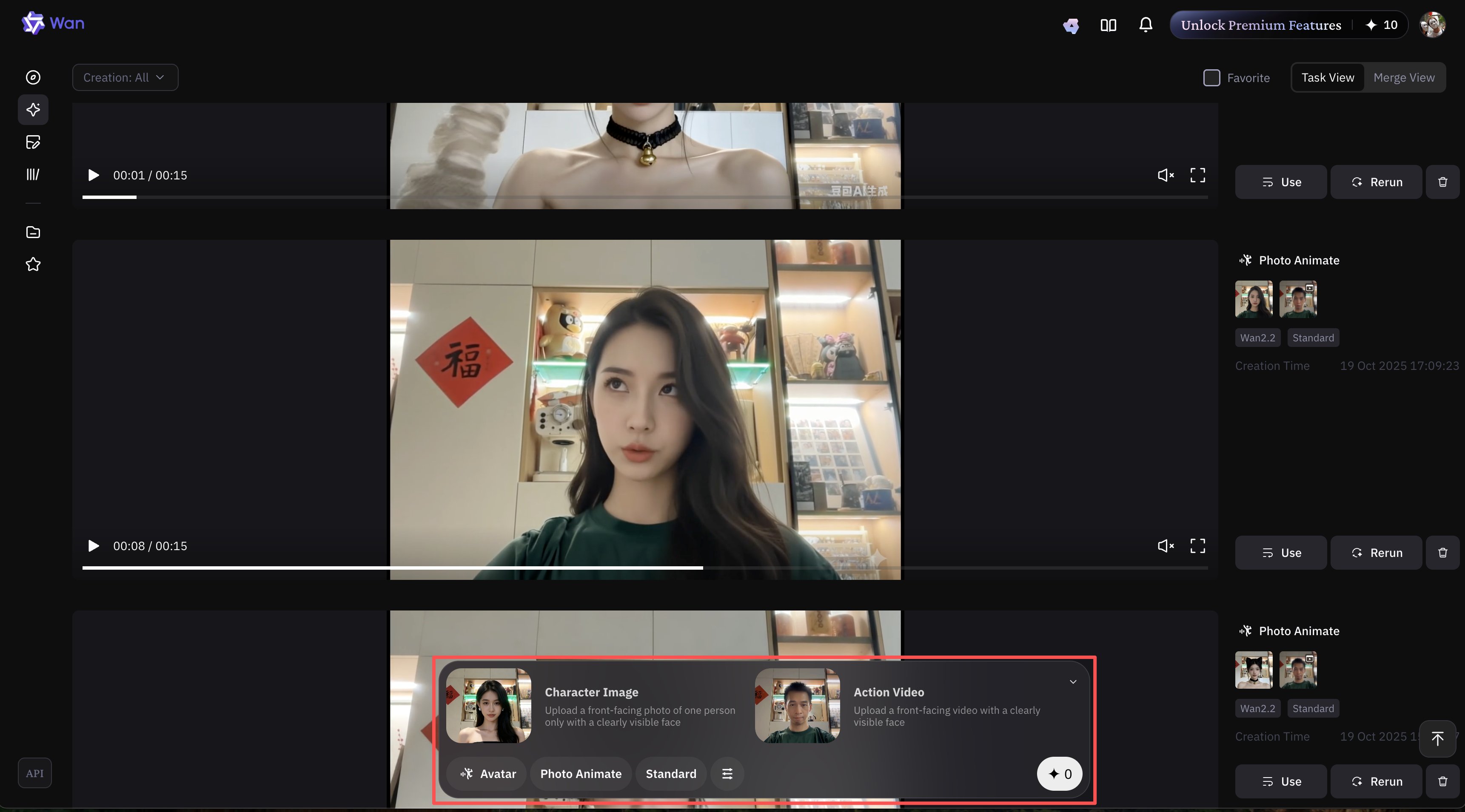
一段你在说话的视频,一张相同分辨率的其他人物的图片,就能通过 AI 把视频中的你换成图片中的人物。

我用 FaceXSwap 提前体验了一把婚纱照,贝克汉姆、布拉德皮特、约翰尼·德普、莱昂纳多轮番来给我当“老公”!
FaceXSwap 这款 iOS 上的 AI 换脸神器,正在用一种“离线流氓”的方式,重新定义你的创意自由!
本文将介绍使用 AVFoundation 与 Metal 渲染 HDR 视频。
本文将介绍 Metal 计算命令编码器。
本文将介绍 Metal 计算命令编码器。
本文将介绍 Metal 渲染上下文。