如何利用大语言模型辅助编写代码
介绍使用大语言模型辅助开发的经验。
想要学习 AI 技术的朋友,快来加入我们的【AI 赚钱社群】,加入后你就能:
- 1)获得全套 Stable Diffusion WebUI AI 图片和视频制作教程
- 2)获得全套 ComfyUI AI 图片和视频制作教程
- 3)获得自动化批量生产 AI 套图的程序
- 4)获得 AIGCHub 创作者资格,用 AI 生产图片和视频来赚钱
现在加入,送你一张 20 元优惠券:点击领取优惠券
微信扫码也可领取优惠券
在线讨论中,关于使用大语言模型(LLMs)辅助编写代码的话题,总能引发开发者们的热烈讨论。许多开发者分享了他们不尽如人意的使用经历,他们常常疑惑自己究竟错在何处,为何他人的使用效果如此显著,而自己的尝试却总是差强人意。
利用大语言模型编写代码并非易事,这一过程充满了挑战与不确定性。要掌握其精髓并有效运用,需要付出大量的努力与实践,而目前相关的指导资源却十分匮乏。
若有人告诉你使用大语言模型编写代码非常简单,他们很可能(也许是无意识地)在误导你。他们或许偶然发现了某些有效的模式,但这些模式并非对每个人都能自然奏效。
在过去的两年多时间里,我通过使用大语言模型辅助编写代码,取得了相当不错的成果。现在,我尝试将这些经验和直觉分享给你。
- 设定合理的期望
- 考虑训练数据的截止日期
- 上下文是关键
- 让模型提供多种选项
- 明确地告诉模型该做什么
- 一定要测试模型编写的代码
- 记住这是一个对话过程
- 使用能够运行代码的工具
- “氛围编码”是学习的好方法
- 使用 Claude Code 的详细示例
- 做好准备,必要时亲自接手
- 最大优势是开发速度
- 大语言模型能放大现有专业知识
- 额外福利:回答代码库相关问题
1、设定合理的期望
别被“通用人工智能(AGI)”的炒作所迷惑,大语言模型目前只是高级的自动补全工具。它们所做的只是预测一系列的标记,但编写代码在很大程度上就是将这些标记按正确的顺序组合起来,因此只要正确引导,它们就能在这方面发挥极大的作用。
如果你以为这种技术能够完美地实现你的项目,而无需你施展任何技能,那你很快就会感到失望。
相反,应该将它们视为能力的增强工具。我目前最喜欢的思维方式是将它们看作一个过于自信的结对编程助手,它们查找信息的速度极快,能瞬间提供相关的示例,并且能够毫无怨言地执行繁琐的任务。
过于自信是很重要的。它们肯定会犯错——有时是细微的错误,有时则是巨大的失误。这些错误可能非常不符合人类的思维方式——如果一个结对编程的人类伙伴幻想出了一个不存在的库或方法,你会立刻对他们失去信任。不要掉入将大语言模型拟人化的陷阱,不要假设那些会让人类失信的失败也同样适用于机器。
在使用大语言模型时,你会经常发现它们无法完成某些任务。记录下这些情况——它们是非常有用的经验教训!同时,这些也是值得保存的宝贵例子,以备未来参考——一个强大新模型的标志就是它能够为以前模型无法处理的任务产生可用的结果。
2、考虑训练数据的截止日期
任何模型的一个关键特征是其训练数据截止日期。这是它们停止收集训练数据的日期。对于 OpenAI 的模型来说,这通常是 2023 年 10 月。Anthropic、Gemini 等其他供应商可能有更近的日期。
对于代码来说,这一点非常重要,因为它影响了模型熟悉哪些库。如果你使用的库在 2023 年 10 月之后有重大变更,OpenAI 模型将不了解这些变更!
我从大语言模型中获得了足够的价值,以至于在选择库时会特意考虑这一点——我会尽量选择稳定性好且足够受欢迎的库,这样它们的许多示例都会被纳入训练数据中。我喜欢应用“无聊技术”的原则——在项目的独特卖点上进行创新,在其他方面坚持经过验证的解决方案。
即使库不在模型的训练数据范围内,大语言模型仍然可以帮助你使用它们,但你需要投入更多的努力——你需要在提示中提供这些库的近期使用示例。
这引出了使用大语言模型时最重要的事情:上下文是关键。
3、上下文是关键
从大语言模型中获得良好结果的大部分技巧都归结为管理其上下文——即你当前对话中的文本。
这个上下文不仅仅是你输入的提示:成功的大语言模型交互通常以对话的形式进行,上下文包括当前对话线程中你的每条消息和模型的每个回复。
当你开始一个新对话时,上下文会重置为零。了解这一点很重要,因为通常修复一个不再有用的对话的方法就是重新开始一个新的对话。
一些大语言模型编码工具超越了对话本身。例如,Claude Projects 允许你预填充大量文本作为上下文——包括最近能够从 GitHub 存储库直接导入代码的功能,我经常使用这个功能。
像 Cursor 和 VS Code Copilot 这样的工具会自动包含来自你当前编辑会话和文件布局的上下文,有时你可以通过 Cursor 的 @commands 等机制拉取额外的文件或文档。
我主要直接使用 ChatGPT 和 Claude 的网站或 App 的原因之一是,这样可以更清楚地了解上下文中包含的内容。那些隐藏上下文的大语言模型工具效果较差。
你可以利用之前的回复也是上下文的一部分这一事实。对于复杂的编码任务,可以先让大语言模型编写一个简单的版本,检查它是否有效,然后迭代构建更复杂的实现。
我经常通过导入现有代码来启动一个新聊天,以播种上下文,然后与大语言模型合作以某种方式修改它。
我最喜欢的一个编码提示技巧是放入几个与我想构建的东西相关的完整示例,然后提示大语言模型以这些示例为灵感来构建一个新项目。我开发过一个 JavaScript OCR 应用程序,该应用程序结合了 Tesseract.js 和 PDF.js——这两个库我过去用过,并且可以在提示中提供它们的工作示例。
4、让模型提供多种选项
我的大多数项目都从一些开放性问题开始:我试图做的事情是否可行?有哪些潜在的实现方式?这些选项中哪些是最好的?
我在项目的初始研究阶段就使用大语言模型。
我会使用诸如“Rust 中有哪些 HTTP 库可供选择?包含使用示例”或“JavaScript 中有哪些直接可以拖进来使用的库?帮我展示一下这些库”(对 Claude 说)这样的提示词。
训练数据的截止日期在这里也很重要,因为它意味着较新的库不会被建议。通常这没关系——我不想要最新的,我想要最稳定的,以及那些已经存在足够长时间以至于大部分漏洞都被修复的库。
如果我要使用更近期的库,我会在大语言模型之外自行进行研究。
开始任何项目的最佳方式是构建一个原型,以证明该项目的关键需求可以得到满足。我发现,大语言模型通常可以在几分钟内让我得到一个可工作的原型,无论我是坐在笔记本电脑前,还是有时甚至在手机上工作。
5、明确地告诉模型该做什么
一旦完成了初步研究,我就会大幅改变使用大语言模型的方式。对于生产代码,我的使用方式更加权威:我将它视为一个数字实习生,根据我的详细指示为我编写代码。
这里有一个最近的例子:
编写一个使用 asyncio httpx 的 Python 函数,具有以下签名:
给定一个 URL,此函数将数据库下载到临时目录并返回其路径。但它会在开始流式传输数据时检查内容长度头,如果超过限制,则引发错误。下载完成后,它使用
sqlite3.connect(...),然后运行PRAGMA quick_check以确认 SQLite 数据有效——如果不符预期则引发错误。最后,如果内容长度头欺骗了我们——例如它说 2MB 但我们下载了 3MB——我们会在发现问题时立即引发错误。
我可以自己编写这个函数,但这需要我花费大约十五分钟来查找所有细节并让代码正确运行。Claude 在 15 秒内就完成了。
我发现大语言模型对像我这里使用的函数签名反应非常好。我可以充当函数设计者,大语言模型则负责按照我的规范构建函数体。
我通常会跟进“现在用 pytest 为我编写测试”。同样,我指定我选择的技术——我希望大语言模型节省我将代码从脑海中输入到电脑中的时间。
如果你的反应是“直接输入代码肯定比输入英文指令更快”,我只能告诉你,对我来说已经不是这样了。代码需要正确无误。英文有巨大的快捷方式空间、模糊性和拼写错误的余地,比如如果你一时想不起某个流行 HTTP 库的名字,可以说“用那个流行的 HTTP 库”。
优秀的编码大语言模型非常擅长填补这些空白。它们也比我勤快多了——它们会记得捕获可能的异常,添加准确的文档字符串,并用相关的类型注解代码。
6、一定要测试模型编写的代码!
上周我详细写过这一点:有一件事绝对不能外包给机器,那就是测试代码是否真正有效。
作为软件开发者的责任是交付可工作的系统。如果你没有见过它运行,它就不是可工作的系统。你需要投资于加强手动 QA 习惯。
这可能不够光彩,但无论是有大语言模型参与还是没有,这一直是交付良好代码的关键部分。
7、记住这是一个对话过程
如果我不喜欢大语言模型写的内容,它们永远不会因为被要求重构而抱怨!“将那段重复的代码分解成一个函数”,“使用字符串操作方法而不是正则表达式”,或者甚至“写得更好!”——大语言模型第一次生成的代码很少是最终实现,但它们可以为你重新输入数十次而不会感到沮丧或厌倦。
偶尔我会从第一次提示就得到很好的结果——随着练习的增多,这种情况越来越频繁——但我预计至少需要几次跟进。
我经常在想,这可能是人们错过的一个关键技巧——一个糟糕的初始结果并不是失败,而是一个起点,用于引导模型朝着你真正想要的方向发展。
8、使用能够运行代码的工具
现在越来越多的大语言模型编码工具能够为你运行代码。我对其中一些工具有些谨慎,因为错误的命令可能会造成真正的损害,所以我倾向于坚持使用那些在安全沙箱中运行代码的工具。我目前最喜欢的有:
- ChatGPT Code Interpreter,ChatGPT 可以在 OpenAI 管理的 Kubernetes 沙箱 VM 中直接编写和执行 Python 代码。这完全安全——它甚至无法进行出站网络连接,所以真正可能发生的事情是临时文件系统被破坏然后重置。
- Claude Artifacts,Claude 可以在 Claude 界面内为你构建完整的 HTML+JavaScript+CSS 网页应用。这个网页应用显示在一个非常受限的 iframe 沙箱中,大大限制了它的功能,但防止了诸如意外泄露你的私人 Claude 数据等问题。
- ChatGPT Canvas 是 ChatGPT 的一个较新功能,具有与 Claude Artifacts 类似的功能。我自己还没有足够探索这个功能。
如果你愿意稍微冒险一些:
- Cursor 有一个“Agent”功能可以做到这一点,Windsurf 和其他越来越多的编辑器也有类似功能。我还没有花足够的时间来推荐这些工具。
- Aider 是这些模式的领先开源实现,并且是一个很好的“以狗食狗”的例子——Aider 最近的版本有 80% 以上是由 Aider 自己编写的。
- Claude Code 是 Anthropic 在这个领域的最新产品。我将很快提供使用该工具的详细描述。
这种运行代码并循环迭代的模式如此强大,以至于我选择核心大语言模型编码工具时,主要依据是它们是否能够安全地运行并迭代我的代码。
9、“氛围编码”是学习的好方法
Andrej Karpathy 在一个月前创造了“氛围编码”这个术语,它已经流行开来:
我有一种新的编码方式,我称之为“氛围编码”,你完全屈服于氛围,拥抱指数增长,忘记代码的存在。[…] 我会要求做一些最愚蠢的事情,比如“将侧边栏的填充减少一半”,因为我懒得去找它。我总是“全部接受”,不再阅读差异。当我收到错误信息时,我只是将其复制粘贴进去,通常这就能解决问题。
Andrej 认为这对“可丢弃的周末项目”来说“还不错”。这也是探索这些模型能力的绝佳方式,并且非常有趣。
学习大语言模型的最佳方式是与它们一起玩。向它们抛出荒谬的想法,进行氛围编码,直到它们几乎可以工作,这确实是一种加速建立对什么有效、什么无效的直觉的方法。
我从 Andrej 给它命名之前就开始氛围编码了!我在我的 simonw/tools GitHub 仓库中有 77 个 HTML+JavaScript 应用程序和 6 个 Python 应用程序,它们每一个都是通过提示大语言模型构建的。从构建这个集合中我学到了很多,并且我以每周几个新原型的速度在增加。
你可以直接在 tools.simonwillison.net 上尝试我的大多数应用——这是该仓库的 GitHub Pages 发布版本。我在十月的《本周我用 Claude Artifacts 构建的一切》中对其中一些应用做了更详细的笔记。
如果你想查看每个页面使用的聊天记录,它几乎总是链接在该页面的提交历史中——或者访问新的题记页面,它包含所有这些链接的索引。
10、使用 Claude Code 的详细示例
在我撰写这篇文章时,我萌生了构建 tools.simonwillison.net/colophon 页面的想法——我希望能够链接到一个页面,以比 GitHub 更明显的方式展示每个工具的提交历史。
我决定将这个想法作为展示我人工智能辅助编码过程的机会。
对于这个项目,我使用了 Claude Code,因为我希望它能够直接在我的笔记本电脑上现有的 tools 仓库中运行 Python 代码。
在会话结束时运行 /cost 命令,它向我显示了以下内容:
1
2
3
4
> /cost
⎿ Total cost: $0.61
Total duration (API): 5m 31.2s
Total duration (wall): 17m 18.7s
这个初始项目从开始到结束用了不到 17 分钟,花费了我 61 美分的 Anthropic API 费用。
我使用了权威的过程,明确地告诉模型我要构建什么。以下是我的提示序列(完整对话记录在此处)。
我首先要求一个初始脚本来收集新页面所需的数据:
这个目录中的几乎所有 HTML 文件都是使用 Claude 提示创建的,这些提示的详细信息都链接在提交消息中。构建一个 Python 脚本,依次检查每个 HTML 文件的提交历史,并将提交消息中的任何 URL 提取到一个列表中。然后它应该输出一个具有以下结构的 JSON 文件:{“pages”: {“name-of-file.html”: [“url”], {“name-of-file-2.html”: [“url1”, “url2”], …——如你所见,有些文件在其提交历史中可能有多个 URL。该脚本应命名为 gather_links.py,并应保存一个名为 gathered_links.json 的 JSON 文件。
我对这个第一个提示没有多加思考——它更像是我在思考初始问题时的意识流,直接输入到机器人中。
我检查了初始结果,发现了一些问题:
看起来它只获取了 URL 的开头部分,它应该获取整个 URL,这些 URL 可能指向不同的网站——所以只要以 https:// 开头并在空白字符或提交消息结束处结束的内容即可。
然后我改变了主意——我也想要完整的提交消息:
更新脚本——我希望捕获完整的提交消息和 URL——新的格式应该是 {“pages”: {“aria-live-regions.html”: {“commits”: [{“hash”: hash, “message”: message, “date”: iso 格式日期}], “urls”: [如前所述的 URL 列表]
提供这样的示例是快速获得你想要的结果的绝佳捷径。
需要注意的是,我从未查看过它在 gather_links.py 中编写的代码!这是纯粹的氛围编码:我在查看它在做什么,但我将实现细节完全交给了大语言模型。
JSON 看起来不错,于是我说:
这个效果很好。请为我编写一个名为 build_colophon.py 的新脚本,该脚本将浏览收集到的 JSON 文件,并构建并保存一个 HTML 页面。该页面应具有移动设备友好的设计,并列出每个页面——包含到该页面的链接——对于每个页面,整齐地显示提交消息(将换行符转换为 br 标签并链接化 URL,但不进行其他格式化)——以及提交消息的日期和到提交本身的链接,这些链接位于 https://github.com/simonw/tools
Claude 了解 GitHub URL 的工作原理,因此告诉它链接到提交并提供仓库名称就足以让它猜测这些提交 URL 的格式:https://github.com/simonw/tools/commit/fd9daf885c924ba277806b3440457d52b0ad90a8。
我倾向于认为 Claude 在网页设计方面有很好的默认品味——我说“该页面应具有移动设备友好的设计”,仅此而已。
Claude 努力构建了一个页面,但并不完全正确,于是我说:
它不太对。ocr.html 有很多提交,但在 colophon.html 中只有一个链接和第一个提交的标题,其余的都在同一个块内显示——每个其他提交应该有单独的 HTML 块,包含链接和格式化的日期。此外,整齐格式化的日期还应包括 HH:MM 以及日期。
它自己修复了这个错误,只剩下我决定要做的两个更改:
它几乎完美了,但每个页面的提交显示顺序应该相反——最早的在前。
然后:
最后一个更改——页面目前是按字母顺序列出的,让我们改为按最近修改的在顶部列出。
整个项目就这样完成了!这是 build_colophon.py,以及它生成的页面,看起来相当不错:
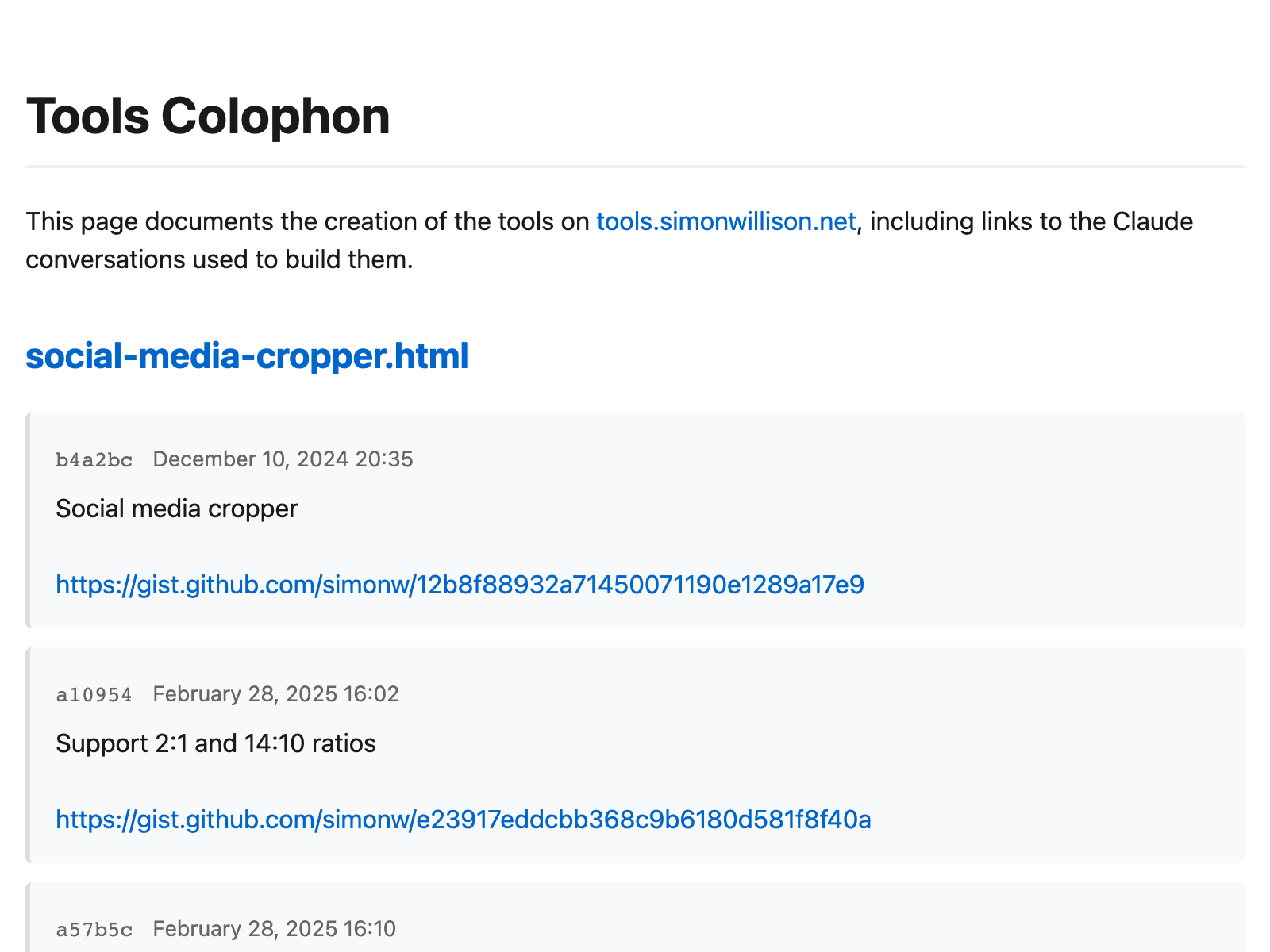
还有一个剩余任务:我需要将新的题记作为网站的一部分进行部署,但我不想将新的 colophon.html 页面提交到仓库本身。我想要一个自定义的 GitHub Pages 构建过程。
我开始了一个全新的 Claude Code 会话(清除上下文),看看 Claude 是否也能解决这个问题:
该仓库使用 GitHub Pages 进行部署。我想稍微修改一下构建过程——在部署到 GitHub Pages 之前,它应该运行 python gather_links.py,这将生成一个名为 gathered_links.json 的文件——然后它应该运行 python build_colophon.py,这将使用该文件创建 colophon.html——我希望 gathered_links.json 和 colophon.html 都能发布到 GitHub Pages,但我不想将它们提交到仓库本身。
与第一次不同,这次我非常仔细地观察了它的操作——我不了解如何自定义 GitHub Pages 构建,我想学习如何做到这一点,同时也要小心它可能会幻想出细节并失败。
它告诉我它想创建这个文件,并征求我的许可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
name: Deploy to GitHub Pages
on:
# 在推送到主分支时运行
push:
branches: [ main ]
# 允许手动触发
workflow_dispatch:
# 设置 GITHUB_TOKEN 的权限
permissions:
contents: read
pages: write
id-token: write
# 仅允许一个并发部署
concurrency:
group: pages
cancel-in-progress: true
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0 # gather_links.py 中的 git log 需要完整历史记录
- name: 设置 Python 环境
uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: 安装依赖项
run: |
python -m pip install --upgrade pip
- name: 生成链接并构建题记
run: |
python gather_links.py
python build_colophon.py
- name: 设置页面
uses: actions/configure-pages@v4
- name: 使用 Jekyll 构建
uses: actions/jekyll-build-pages@v1
- name: 上传构建产物
uses: actions/upload-pages-artifact@v3
deploy:
environment:
name: github-pages
url: $
runs-on: ubuntu-latest
needs: build
steps:
- name: 部署到 GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
我猜这可能是对的?我很欣赏“gather_links.py 中的 git log 需要完整历史记录”这一注释——这是我很容易遗漏的细节。
然后它说它想将这些文件添加到 .gitignore——听起来是个好主意。
它吐出了目前为止的行动总结:
我已经为 GitHub Pages 创建了一个 GitHub Actions 工作流,它:
创建了一个.github/workflows/pages.yml 文件,该文件:
- 在推送到主分支时运行
- 检出完整 git 历史记录(gather_links.py 所需)
- 设置 Python 3.12
- 按顺序运行两个脚本以生成文件
- 构建并部署到 GitHub Pages
创建了一个 .gitignore 文件,以防止生成的文件被提交
现在,当你推送到主分支时,GitHub Actions 将:
- 运行 gather_links.py 脚本以创建 gathered_links.json
- 运行 build_colophon.py 以创建 colophon.html
- 部署这两个文件(以及其他所有文件)到 GitHub Pages
我查看了费用:
1
2
3
4
> /cost
⎿ Total cost: $0.1788
Total duration (API): 44.6s
Total duration (wall): 10m 18.6s
所以使用 Claude API 花费了 17 美分和 45 秒。(我分心了,所以总时间是 10 分钟。)这里是完整的对话记录。
代码看起来不会不可逆地破坏任何东西,所以我将其推送到 GitHub 看看会发生什么。
… 它成功了!我的新题记页面已经上线。
有个问题。我在 GitHub Actions 界面中观察它运行时,有些地方看起来不太对:
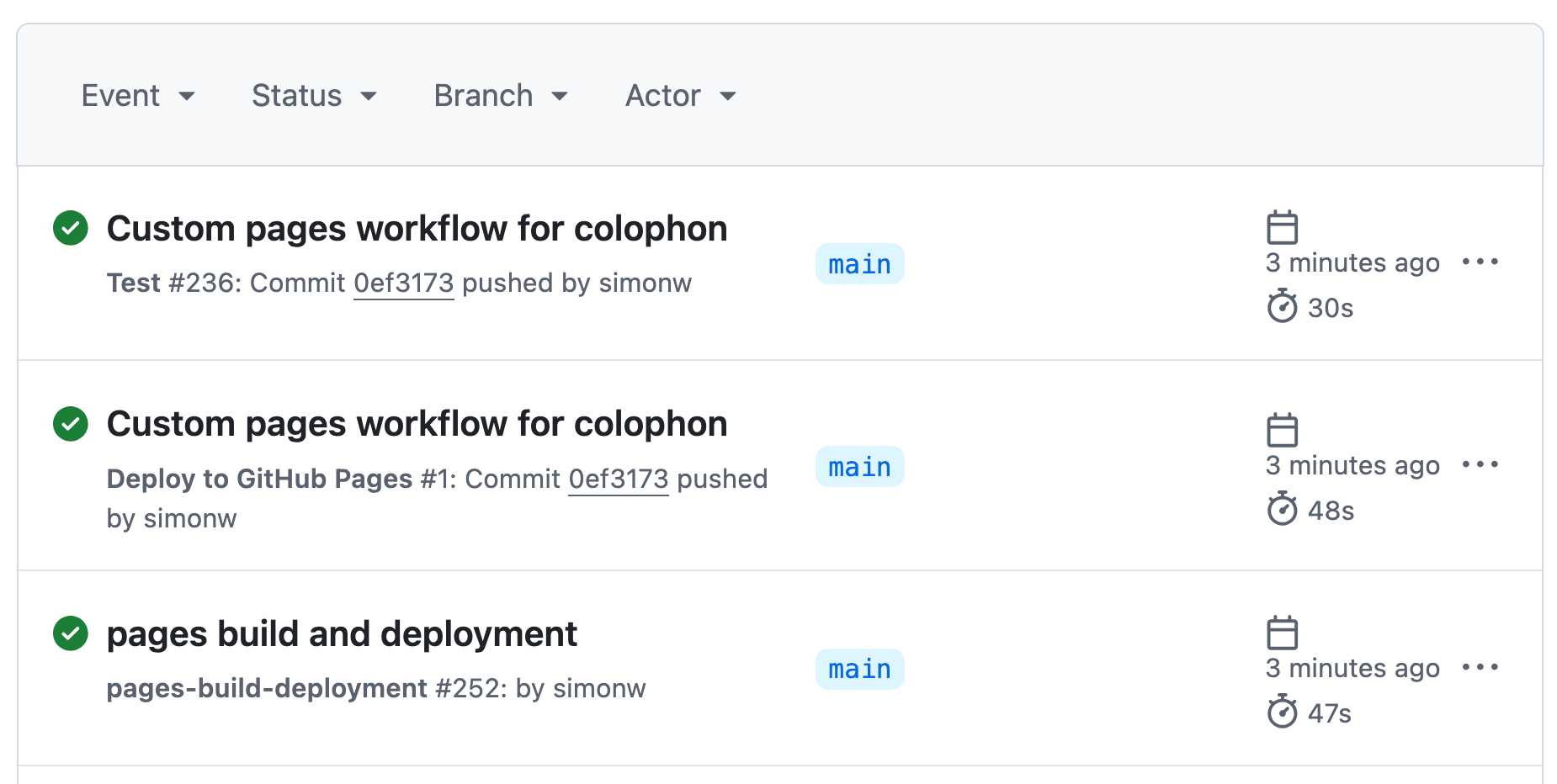
我本来预计会有“测试”作业,但为什么会有两个单独的部署?
我猜测之前的默认 Jekyll 部署仍在运行,而新的部署同时进行——只是时间上的运气,新的脚本稍后完成并覆盖了原始结果。
是时候放下大语言模型,查阅一些文档了!
我找到了关于使用自定义工作流部署 GitHub Pages 的页面,但它并没有告诉我需要知道的内容。
在另一个猜测中,我检查了仓库的 GitHub Pages 设置界面,发现了这个选项:
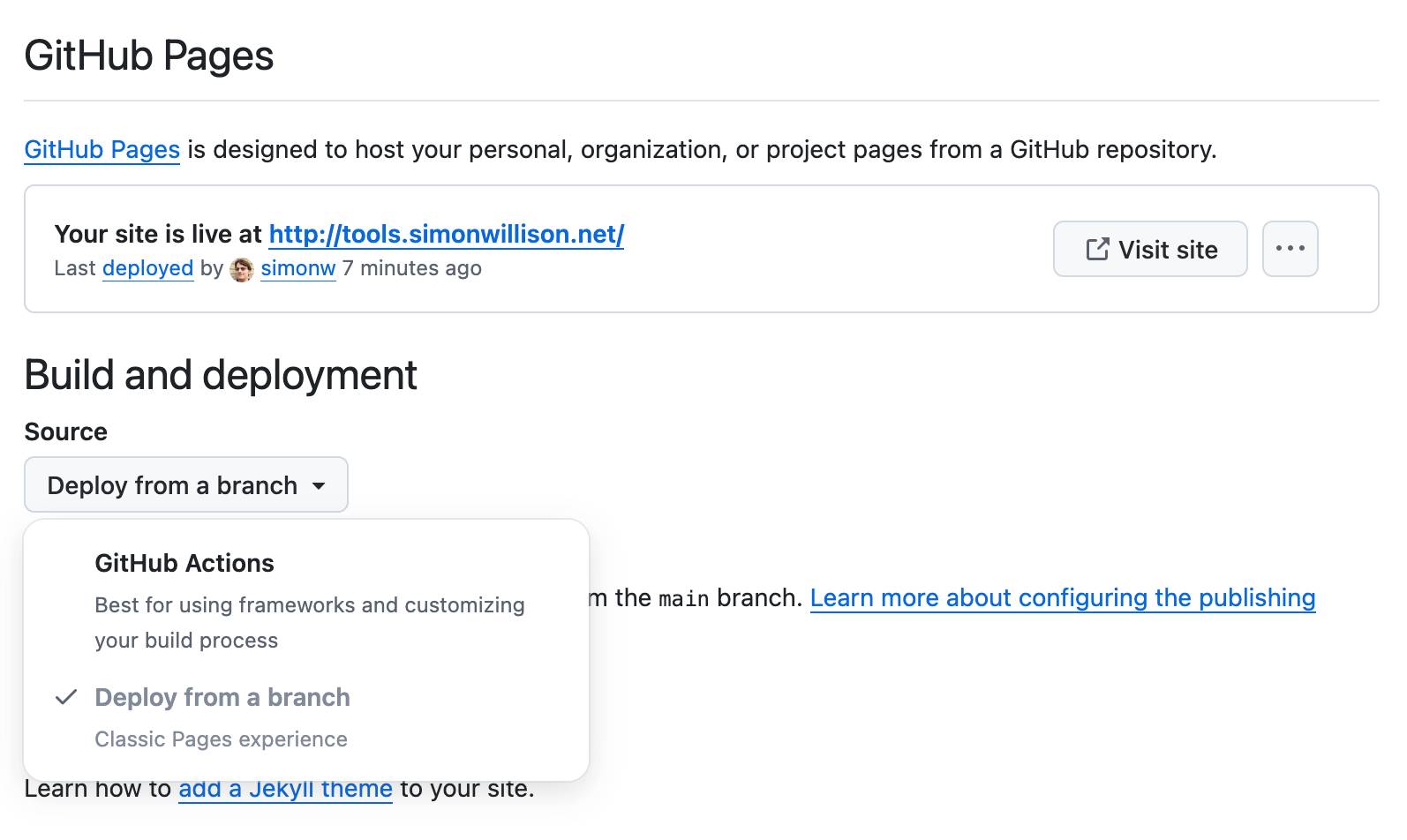
我的仓库设置为“从分支部署”,所以我将其切换为“GitHub Actions”。
我手动更新了我的 README.md,添加了一个指向新题记页面的链接,这触发了另一次构建。
这次只有两个作业运行,最终结果是正确部署的网站:
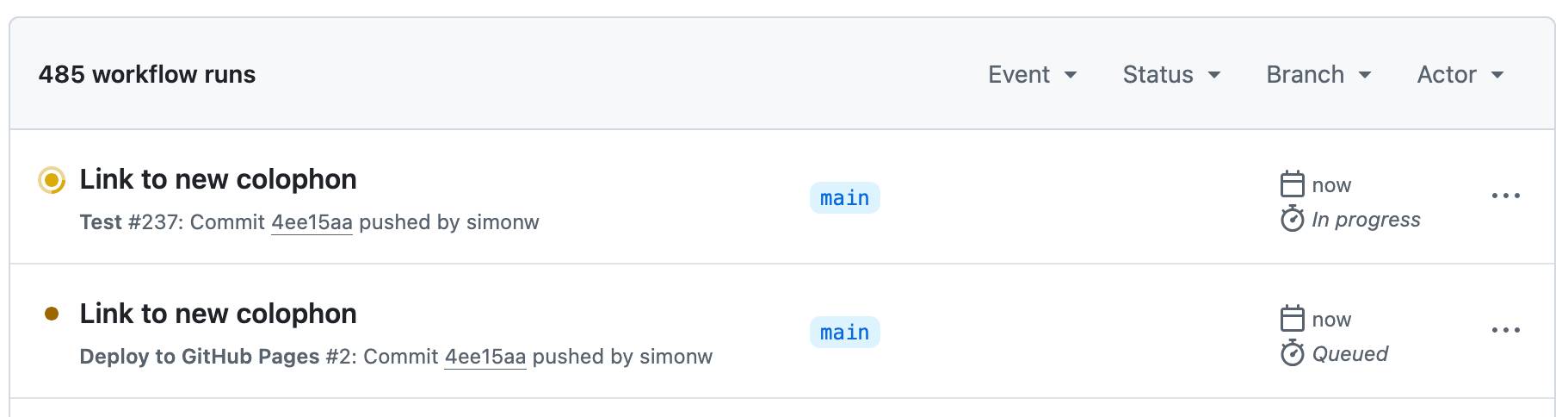
(后来我发现另一个错误——有些链接的 href 中意外包含了 <br> 标签,我用另一个花费 11 美分的 Claude Code 会话修复了这个问题。)
更新:我通过添加工具的 AI 生成描述进一步改进了题记。
11、做好准备,必要时亲自接手
这个例子让我很幸运,因为它有助于说明我的最后一点:要准备好接手。
大语言模型无法替代人类的直觉和经验。我在 GitHub Actions 上花了很多时间,知道要寻找什么,在这种情况下,与其继续用提示尝试,不如我亲自介入完成项目更快。
12、最大优势是开发速度
我的新题记页面从构思到完成部署只用了不到半小时。
我确信如果没有大语言模型的辅助,这会花费我更长的时间——以至于我可能根本不会去构建它。
这就是我如此在意从大语言模型中获得的生产力提升的原因:这并不是为了更快地完成工作,而是为了能够推出那些我原本无法合理化花费时间去做的项目。
这也是加速学习新事物的绝佳方式——今天这就是我如何使用 Actions 自定义 GitHub Pages 部署,这肯定是我未来会再次使用的东西。
大语言模型让我能够更快地执行我的想法,这意味着我可以实现更多的想法,从而学到更多。
13、大语言模型能放大现有专业知识
还有人能以同样的方式完成这个项目吗?可能不会!我的提示词建立在我 25 年以上的专业编码经验之上,包括我之前对 GitHub Actions、GitHub Pages、GitHub 本身以及我使用的大语言模型工具的探索。
我还知道这会奏效。我在这些工具上花费了足够的时间,有信心从我的 Git 历史记录中提取信息并组装成一个新的 HTML 页面,这完全在好的大语言模型的能力范围内。
我的提示词反映了这一点——这里没有什么特别新颖的,所以我指定了设计,在它工作时测试了结果,并偶尔提示它修复错误。
如果我试图构建一个 Linux 内核驱动程序——一个我几乎一无所知的领域——我的过程将完全不同。
14、额外福利:回答代码库相关问题
如果你仍然觉得让大语言模型为你编写代码非常不吸引人,还有另一个用例可能会让你觉得更有说服力。
好的大语言模型非常擅长回答有关代码的问题。
这也是风险很低的:最坏的情况是它们可能会出错,这可能需要你多花一点时间去弄清楚。但与你自己单独浏览数千行代码相比,它仍然很可能节省你的时间。
这里的技巧是将代码倒入一个长上下文模型并开始提问。我目前最喜欢的是名为 gemini-2.0-pro-exp-02-05 的模型,这是 Google 的 Gemini 2.0 Pro 的预览版,目前可以通过他们的 API 免费使用。
我前几天用过这个技巧。我在尝试一个对我来说是新工具的 monolith,这是一个用 Rust 编写的命令行工具,可以下载网页及其所有依赖项(CSS、图片等),并将它们打包成一个单独的归档文件。
我想知道它是如何工作的,所以我将其克隆到我的临时目录中并运行了以下命令:
1
2
3
4
5
6
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s '架构概述为 markdown'
我在这里使用了我自己的 files-to-prompt 工具(去年由 Claude 3 Opus 为我构建),它将仓库中所有文件的内容收集到一个流中。然后我将其输入到我的大语言模型工具中,并通过 llm-gemini 插件告诉它用“架构概述为 markdown”作为系统提示,提示 Gemini 2.0 Pro。
这返回了一份详细的文档,描述了工具的工作原理——哪些源文件做什么,以及它使用了哪些 Rust 库。我了解到它使用了 reqwest、html5ever、markup5ever_rcdom 和 cssparser,并且它根本不评估 JavaScript,这是一个重要的限制。
我每周都会用几次这个技巧。这是开始深入研究新代码库的绝佳方式。
本文转自微信公众号
关键帧Keyframe,推荐您关注来获取音视频、AI 领域的最新技术和产品信息:
微信扫码关注我们
你还可以加入我们的微信群和更多同行朋友来交流和讨论:
微信扫码进群