AI 教程:利用自有数据集训练 LoRA 模型
这里我们就来介绍一下如何训练自己的 LoRA 模型。
向你推荐 FaceXSwap:On-Device Offline AI Face Swap for Free
在 iPhone 上直接对照片、GIF 动图、视频中的人脸实现快速换脸。无需上传任何数据,确保完全隐私与安全。即时、安全、无限次数、功能强大,现在即可免费试用。
在 AppStore 搜索 ‘facexswap’
- FaceXSwap 官网:https://facexswap.com
- FaceXSwap iOS App 下载:https://apps.apple.com/app/id6752116909
除了使用网络上开放出来的各种模型外,我们还可以基于自有数据来训练我们自己的模型来生成独特的 AI 绘画作品,其中最常见的就是训练 LoRA 模型。LoRA 是一种成本较低的微调模型训练方法,可以对主模型进行微调,从而支持生成特定的人像、物品以及画风。训练 LoRA 模型对设备配置要求较低,训练速度相对较快,产出的模型大小也不大,所以是一种不错的选择。
这里我们就来介绍一下如何训练自己的 LoRA 模型。
1、准备训练数据
训练自己的 LoRA 模型之前,首先要明确你这个 LoRA 模型的用途是用于支持生成特定的人像、物品还是画风。接下来就需要准备和预处理将要训练的数据,这部分工作包括:
- 1)准备用于训练的图片
- 2)按标准处理图片的分辨率
- 3)对图片进行打标
1.1、准备用于训练的图片
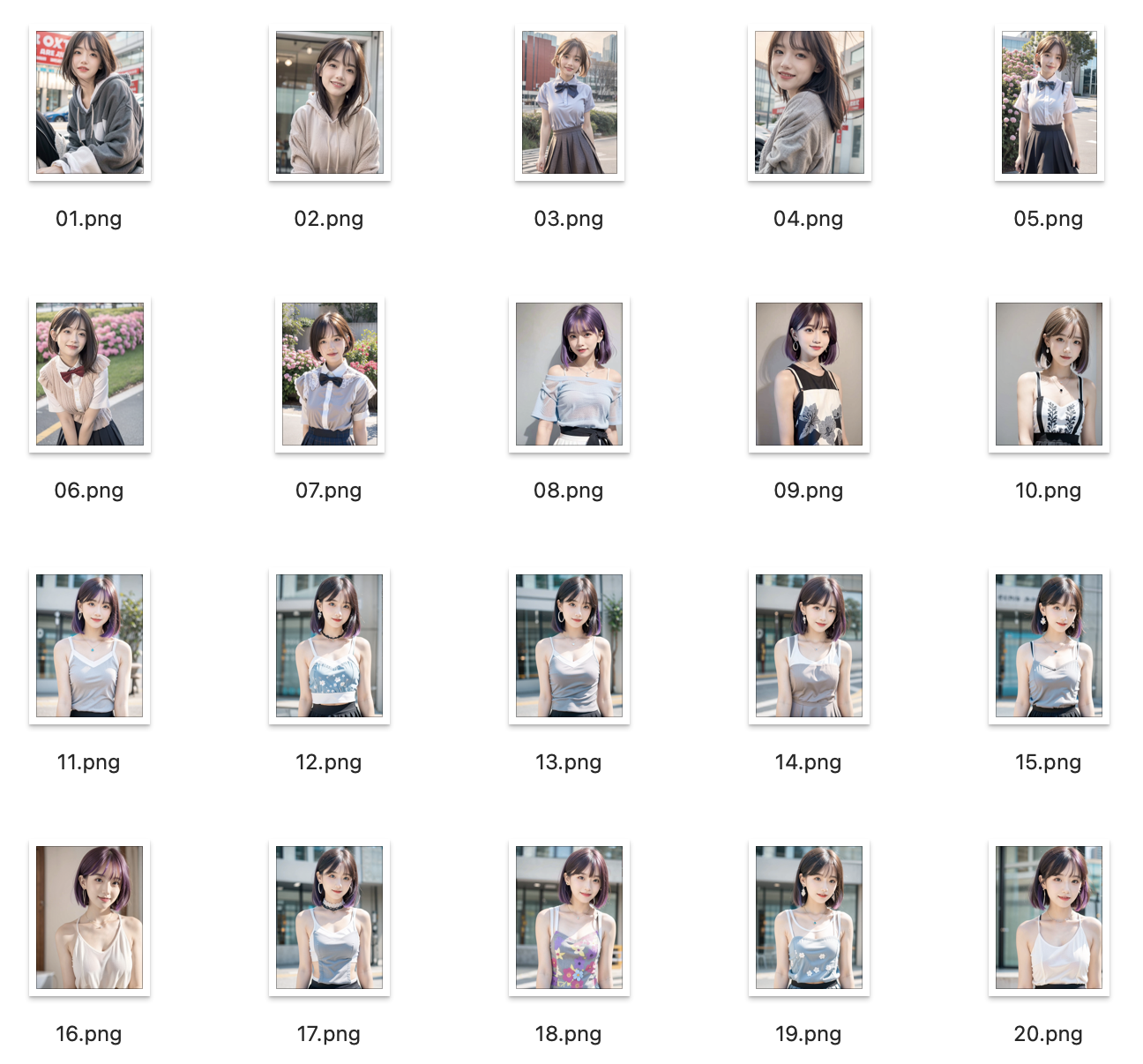
我们这里以训练人像 LoRA 为例来准备图片训练集,一般需要注意以下几点:
- 图片质量:保证图片尽量清晰,人像主体要突出,画面中保持元素简洁结构简单。
- 特征维度:对于训练人像 LoRA 可以从表情、身体姿态、装扮、视角、场景、光照条件等维度提供较丰富的训练集。
- 图片数量:训练 LoRA 模型一般是要求每张图最少训练 100 步,总步数不低于 1500 步,这样算下来建议训练集的图片数量要大于 15 张,一般最好 20 张以上。当然训练集的图片多一些,特征维度丰富一些效果会更好,但是训练的时间就要更久了。
- 图片分辨率:训练集的图片要把分辨率处理成一致的,基于 Stable Diffusion 主模型来训练 LoRA 模型一般可以采用
512x512、768x768这几种分辨率。
下面是我们为训练人像 LoRA 准备的训练集:
1.2、按标准处理图片的分辨率
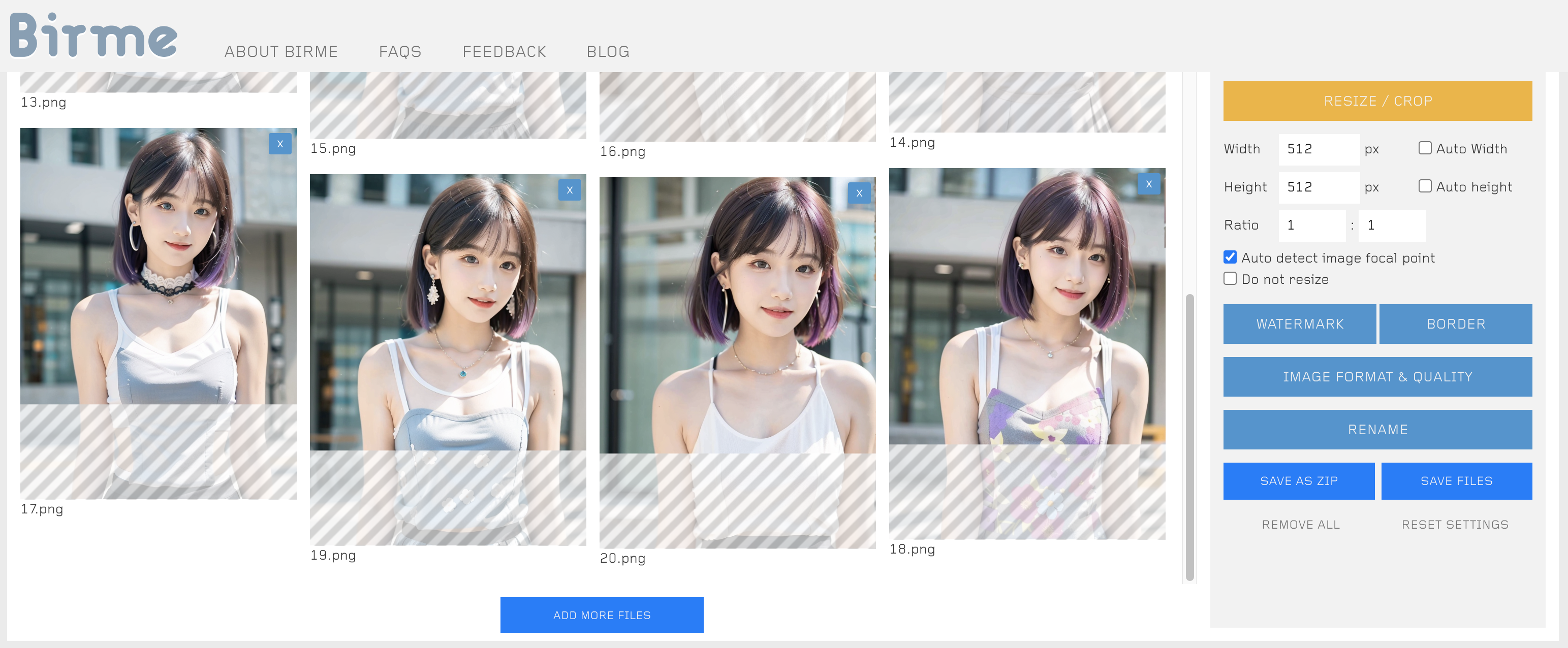
在准备训练数据时,我们遇到比较多的问题是收集到图片的分辨率各异,如果图片较多时处理起来还比较耗时,这里推荐一个在线批量处理图片分辨率的工具站:https://www.birme.net/。
下面我们在 https://www.birme.net/ 上将训练集图片的分辨率统一预处理为 512x512,如图:
1.3、对图片进行打标
完成对图片素材的预处理,接下来就是对图片进行打标来辅助模型训练。
这里我们可以使用 Stable Diffusion WebUI 的图片预处理给图片打标,使用方法如图:
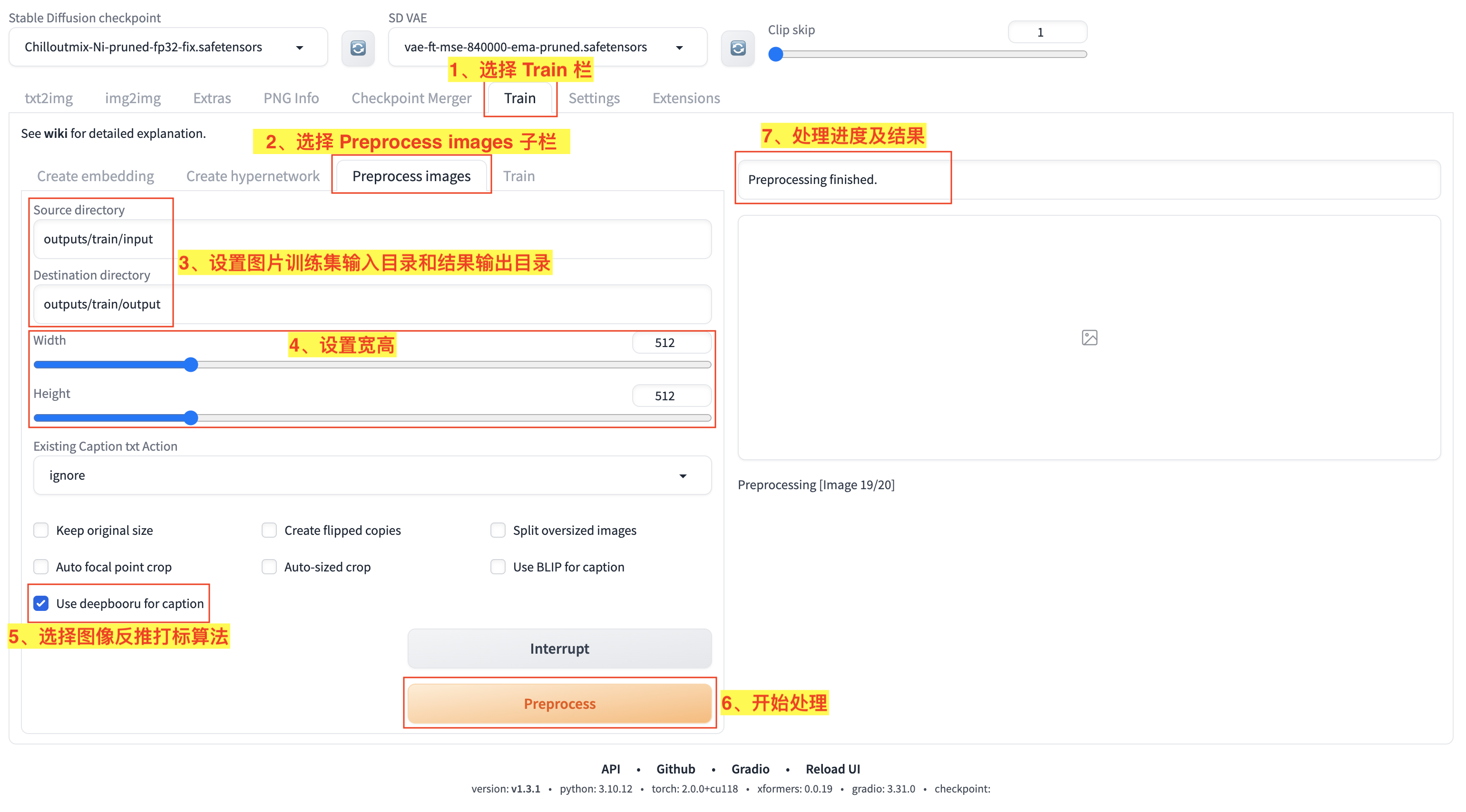
- 1)在 WebUI 中选择
Train主栏; - 2)打开
Train栏功能页面后,选择Preprocess images子栏; - 3)设置图片训练集所在的
输入目录(Source directory)和图片处理后的输出目录(Destination directory); - 4)设置预处理输出图片宽高;
- 5)选择
Use deepbooru for caption来给训练集图片打标; - 6)点击
Preprocess开始进行预处理; - 7)等待处理进度和结果,处理完成后,就可以在
输出目录(Destination directory)看到预处理后的输出图片及打标数据。
下面是输出图片及打标数据:
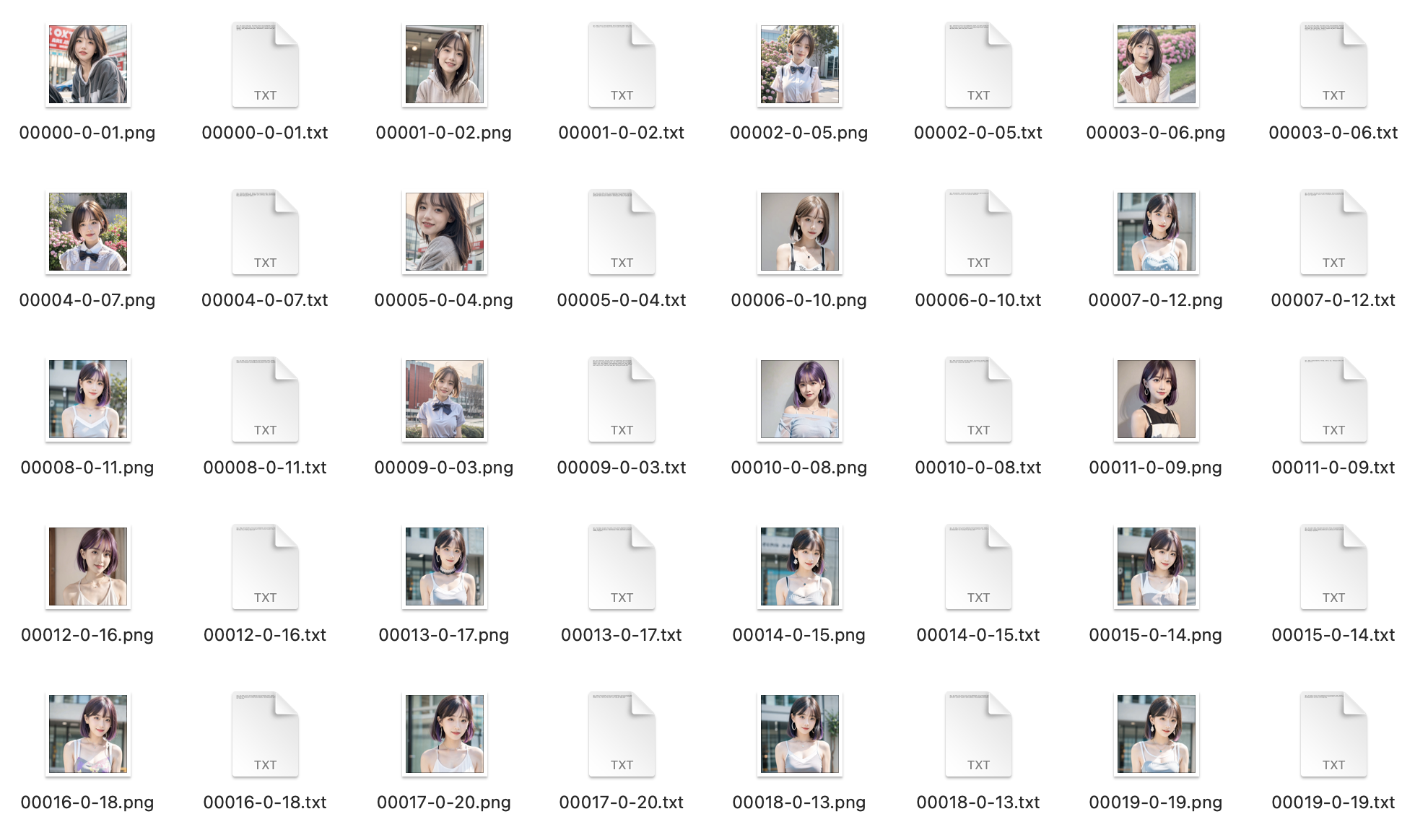
可以看到上述处理过程为每张图片生产了一个 txt 打标文件。
我们看一下其中一张图片和对应的打标:

1girl, 3d, bicycle, black_eyes, blur_censor, blurry, blurry_background, blurry_foreground, bokeh, brown_hair, building, bus, car, chromatic_aberration, city, cosplay_photo, depth_of_field, film_grain, focused, ground_vehicle, hood, hood_down, hooded_jacket, hoodie, lips, looking_at_viewer, motion_blur, motor_vehicle, outdoors, people, photo_\(medium\), photo_background, photo_inset, photorealistic, realistic, short_hair, solo, stadium, storefront, street, upper_body
对于通过算法生成的打标,我们还可以继续检查和优化,我们可以将其中部分特征标签删掉,或者调整和替换一些词语。
当我们删除某一些特征标签词,就表示我们希望这个特征与 LoRA 模型绑定,而不希望以后可以通过提示词对该特征进行调整改变;如果我们保留对应的标签词,则相反,是希望这个特征可以在以后用提示词进行引导和调整。
比如,在上面的标签词中有 black_eyes 和 brown_hair 两个表示人物特征的词,如果我们希望训练的人物始终保持黑眼睛和棕头发的特征,我们就可以删掉这两个标签词,使得这两个特征与 LoRA 模型绑定;如果我们以后在使用这个模型时还可以通过类似 blue eyes、yellow hair 这样的提示词来改变人物的眼睛颜色和头发颜色,我们就可以保留这两个标签词。
当然,我们也可以省事不管这些算法生成的打标。
至此,我们就完成了对训练数据的准备。
2、搭建训练工具
训练 LoRA 的方案有很多种,我们这里介绍一种:基于 https://github.com/Linaqruf/kohya-trainer 项目来训练 LoRA 模型。
我们在 kohya-trainer 项目的 github 页面打开对应的 Colab 地址,如图:
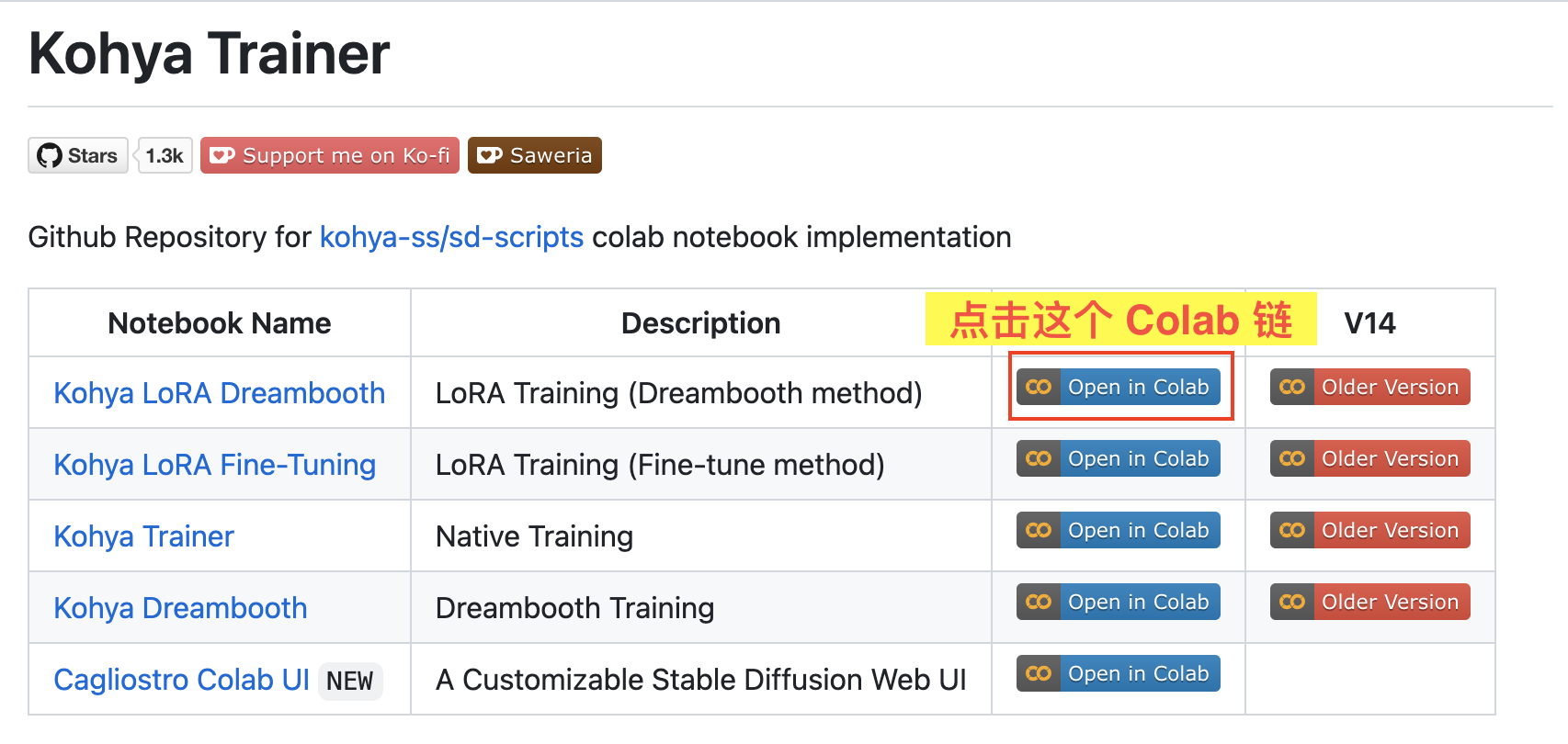
- 打开 https://github.com/Linaqruf/kohya-trainer,点击
Kohya LoRA Dreambooth对应的 Colab 链接。
使用 Colab 需要登录 Google 账号,如图:
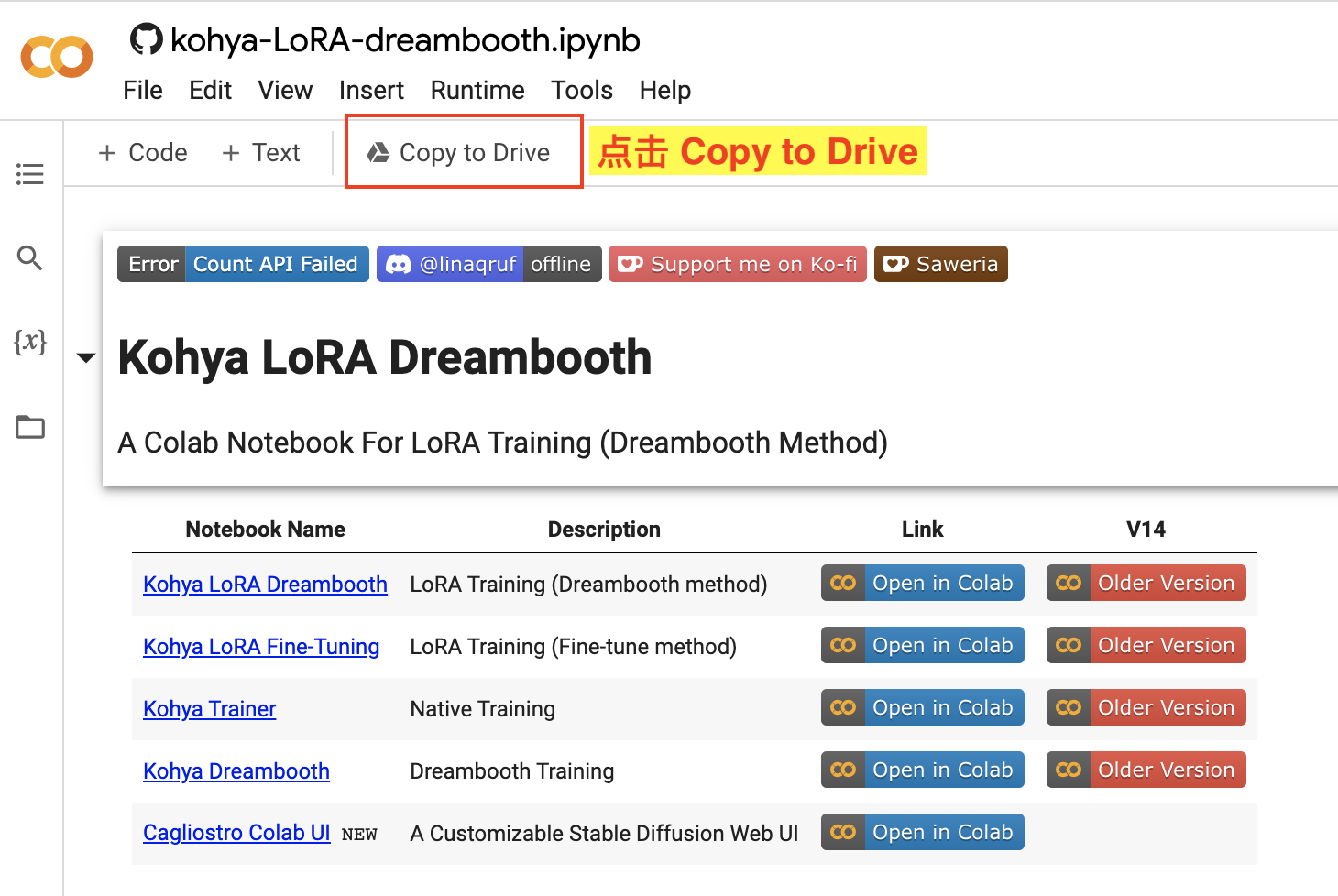
- 登录 Google 账号,在页面上点击
Copy to Drive将该流程拷贝到自己的 Google Drive 云盘上。
这样我们后面就可以在自己拷贝的这份流程上来操作,并且所有的参数都会被保存下来再后续可以重复使用。
接下来我们按照步骤一步一步来操作。
3、训练 LoRA 模型
3.1、安装训练程序
首先我们来到 I. Install Kohya Trainer 来安装 Kohya 训练程序。
首先安装依赖,如图:
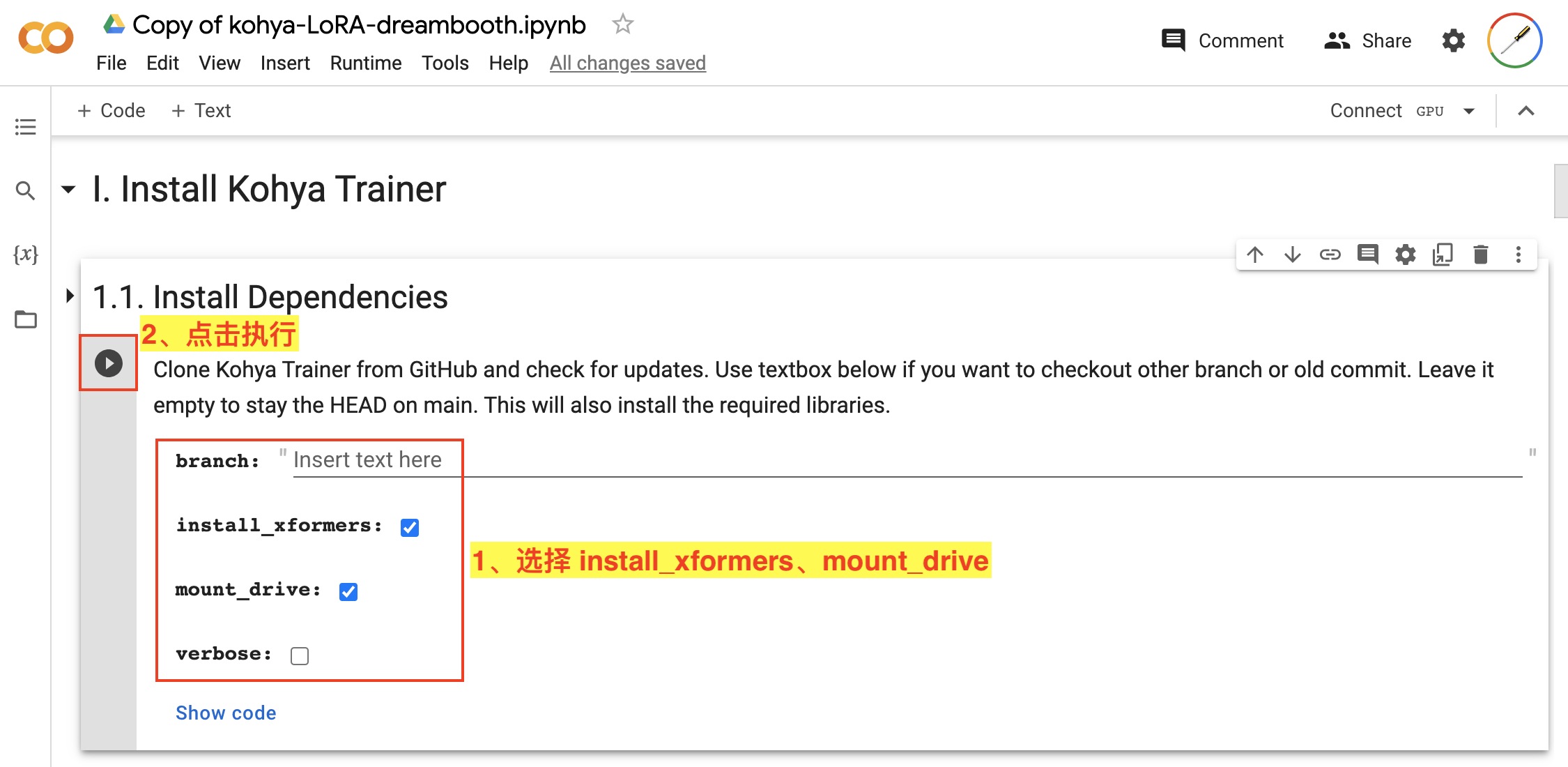
- 在
1.1. Install Dependencies步骤中选择install_xformers和mount_drive; - 点击该步骤的执行按钮。
这里需要用到 Google Drive,如图:
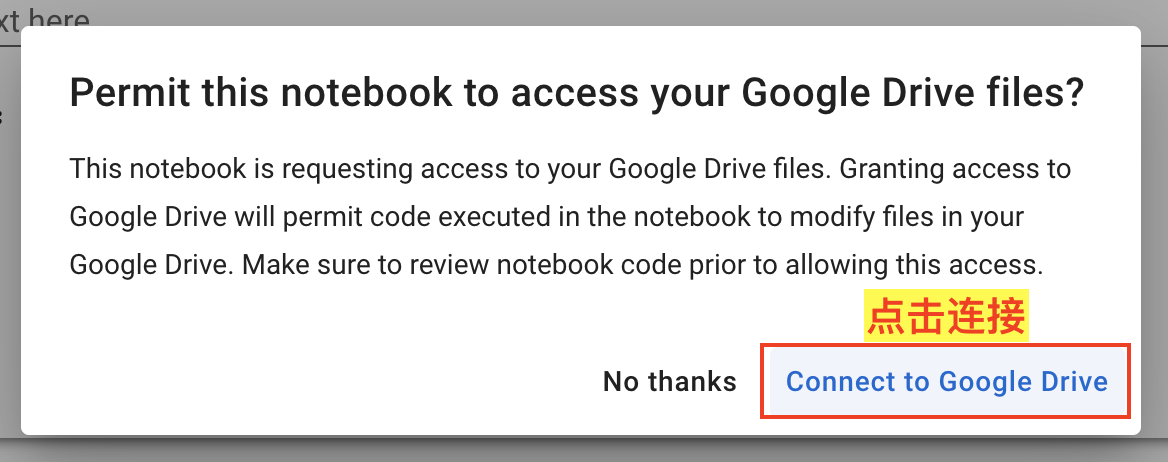
- 在弹出的对话框中选择
Connect to Google Drive,并完成后续授权登录操作,如果运行过程遇到报错可以重试一下。
3.2、下载模型
接下来我们来到 II. Pretrained Model Selection 来选择下载预训练需要的模型。这里可以下载相关的主模型及 VAE 模型,大家可以按需选择。
我们这里还是基于 Stable Diffusion v1.5 来训练,选择设置如图:
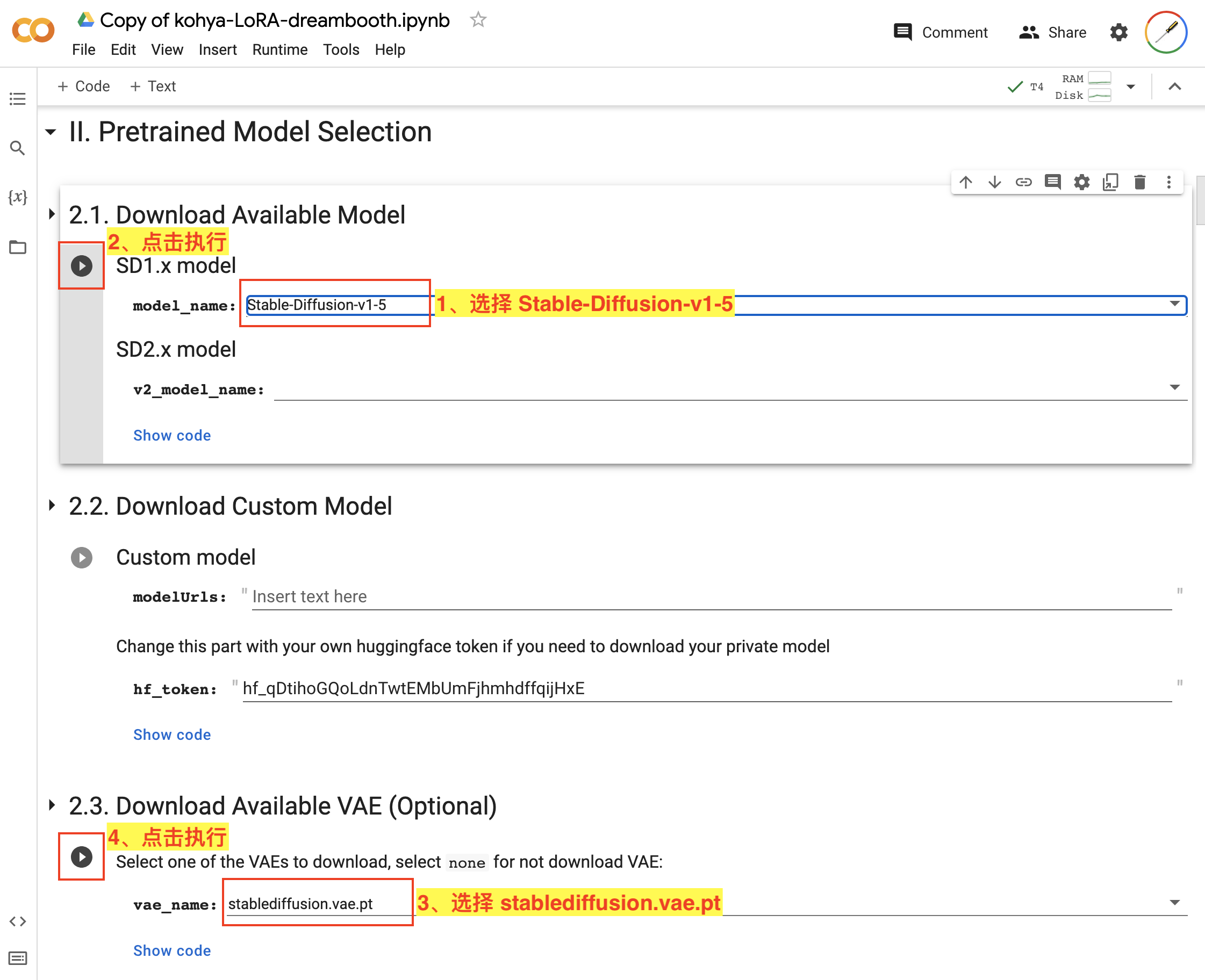
- 在
2.1. Download Available Model中,我们选择 SD1.x 模型中的Stable-Diffusion-v1-5; - 点击该步骤的执行按钮;
- 在
2.3. Download Available VAE (Optional)中,我们选择stablediffusion.vae.pt; - 点击该步骤的执行按钮。
3.3、训练数据上传
完成了模型配置和下载,接下来就可以上传训练数据了,我们来到 III. Data Acquisition。
首先要设置训练数据存储目录,如图:
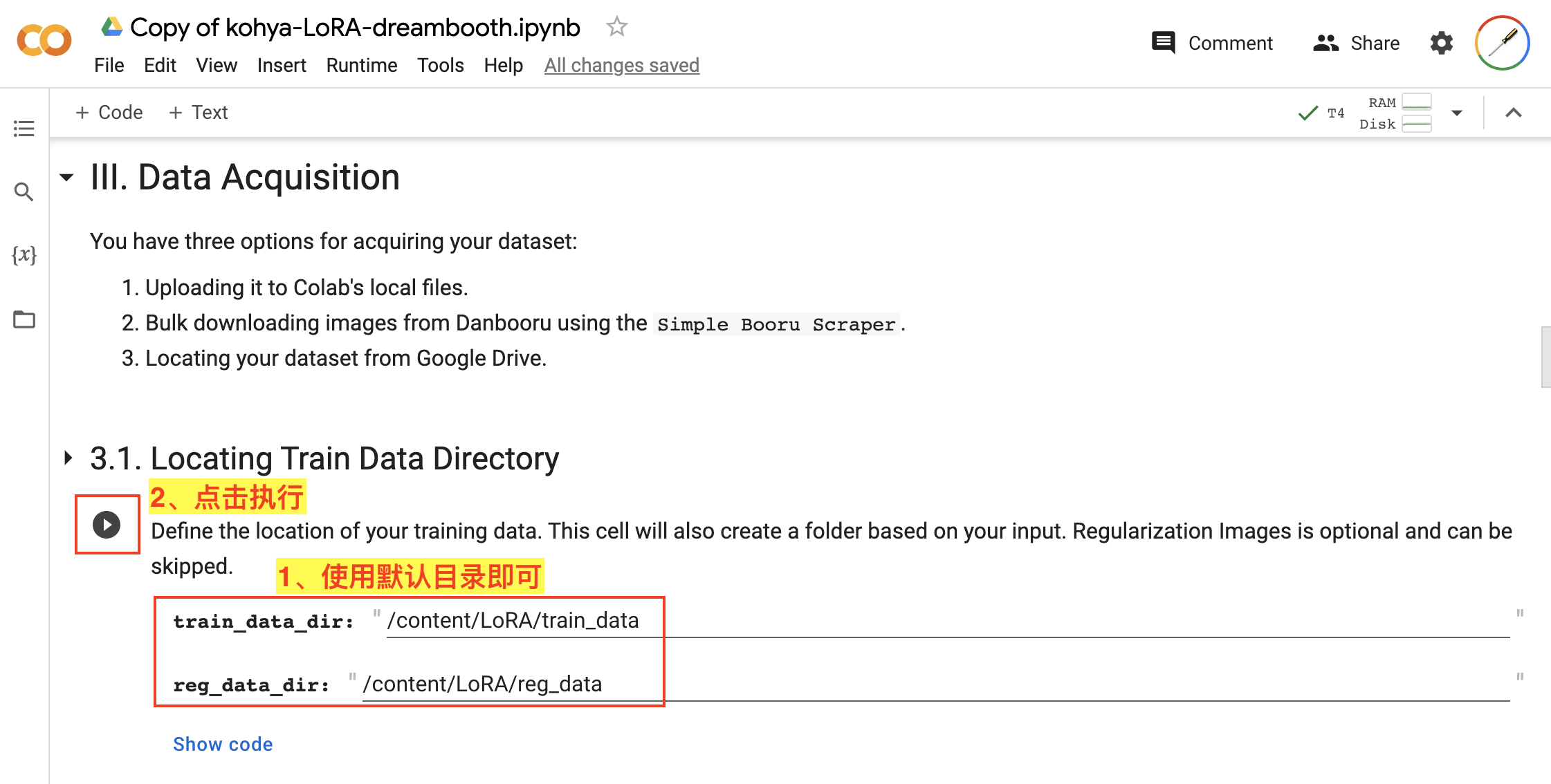
- 在
3.1. Locating Train Data Directory中,对于train_data_dir和reg_data_dir直接使用默认目录就行; - 直接点击该步骤的执行按钮。
接下来来到 3.2. Unzip Dataset,这里需要我们上传训练数据的 zip 压缩包。在这之前我们先要在 Google Drive 上创建一个文件夹,如图:
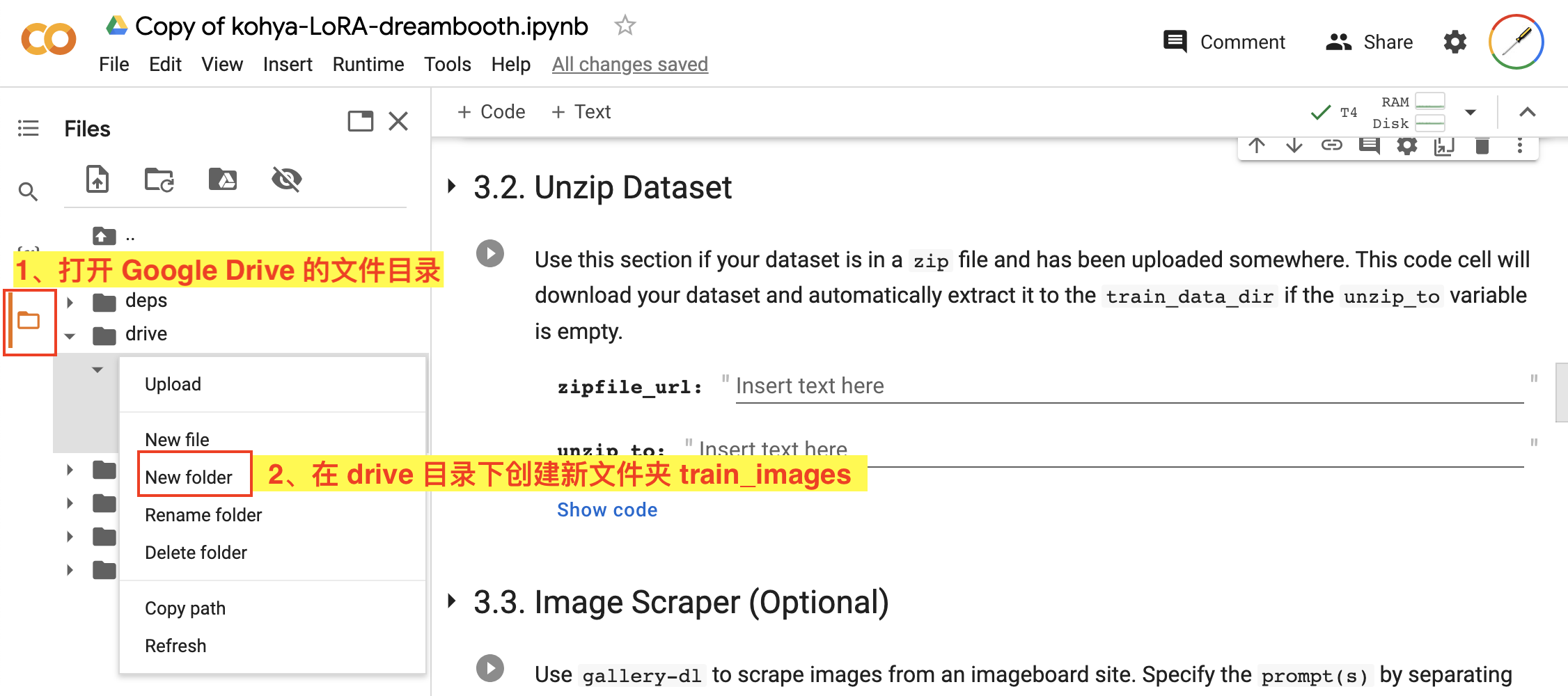
- 点击边栏的文件夹按钮,打开 Google Drive 的文件目录;
- 右键点击
drive文件夹后,在弹出的功能框中使用New folder创建一个新文件夹用来上传我们的训练数据,我们这里的目录名就叫train_images;
接下来,我们开始上传数据,如图:
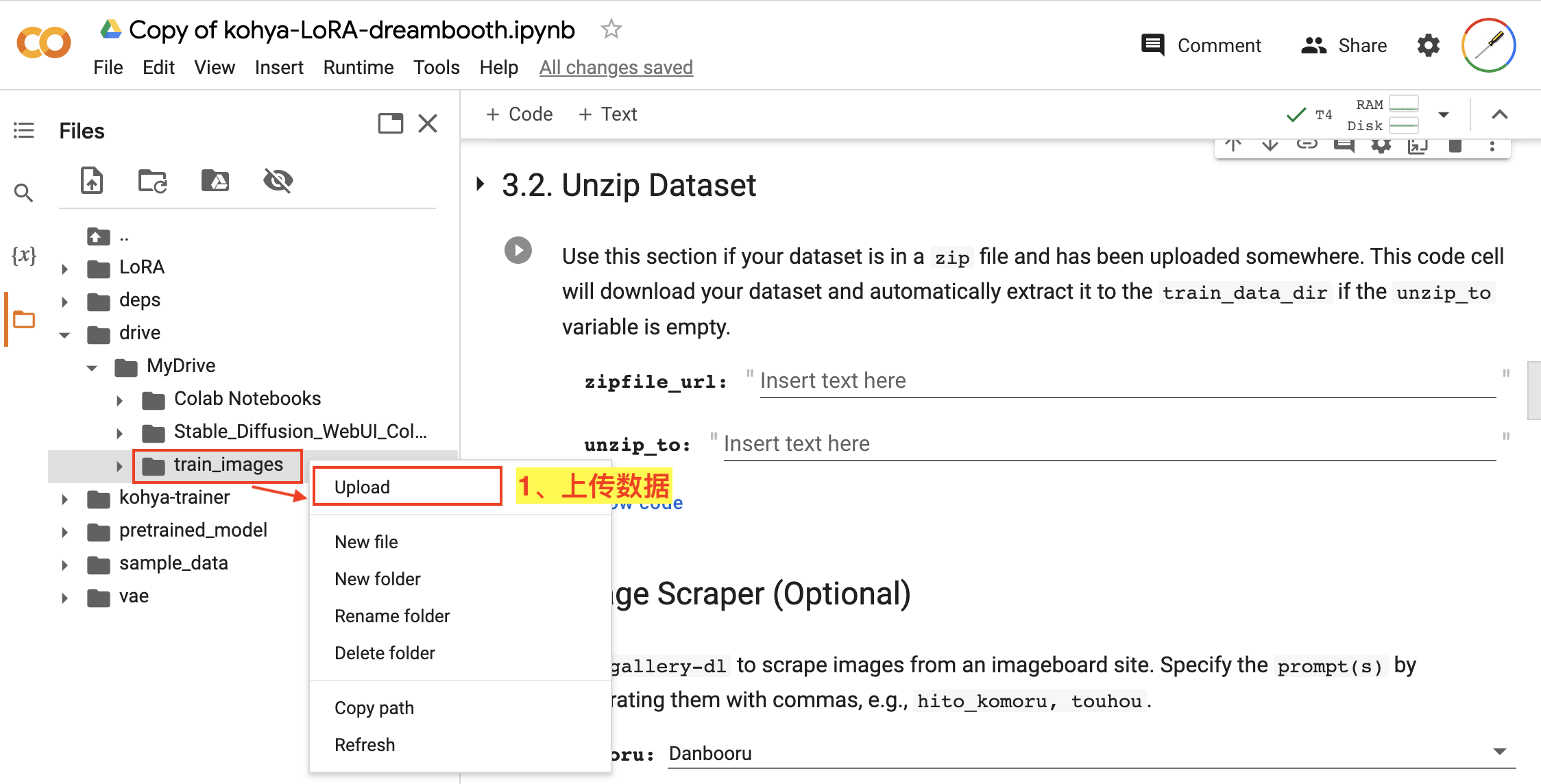
- 右键点击我们刚才新创建的
train_images目录,在弹出的功能框中使用Upload功能上传我们已经准备好的训练数据zip压缩包。
完成数据上传后,就可以把数据解压到待处理的目录了,如图:
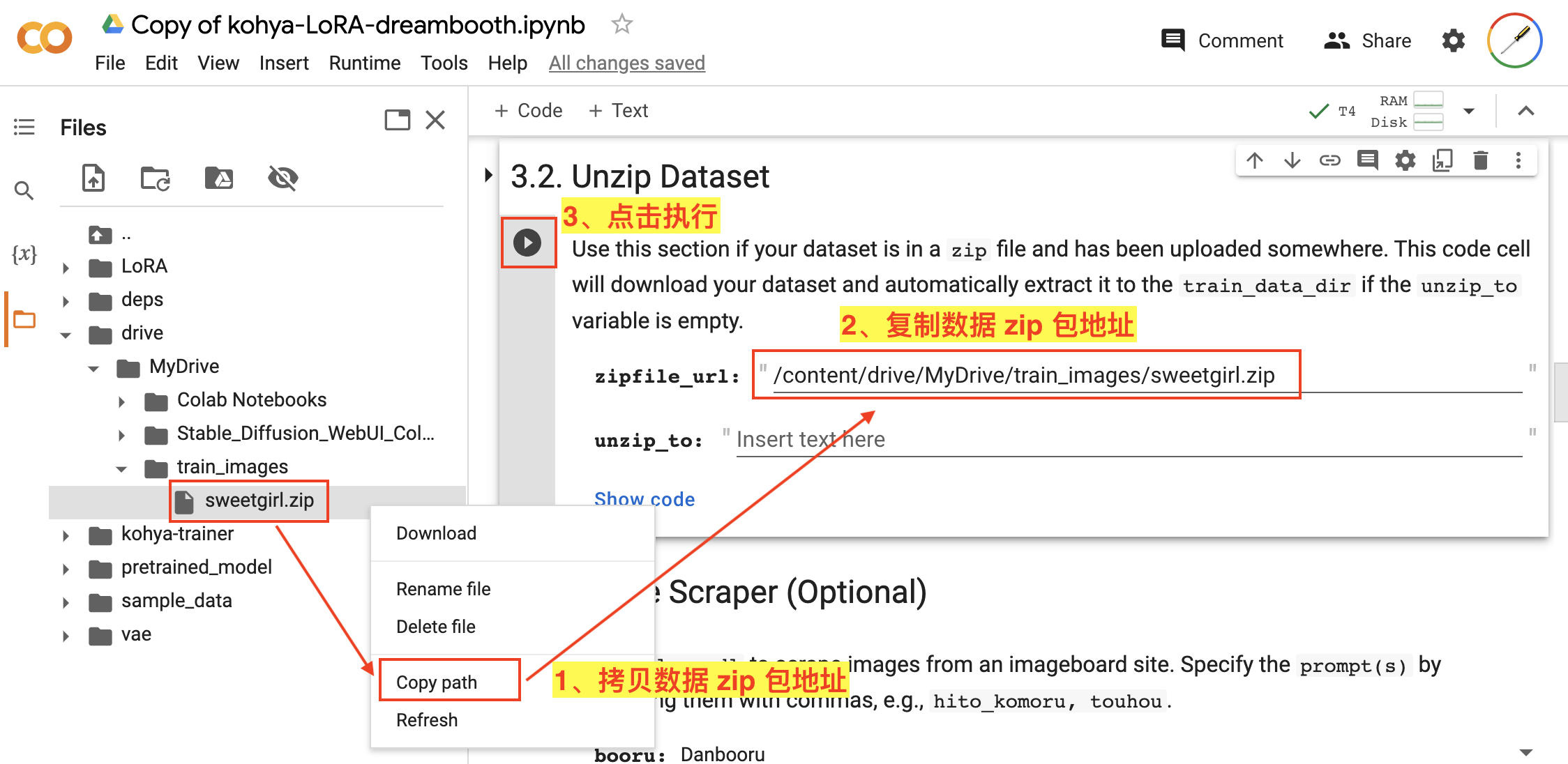
- 右键点击我们刚才上传的数据 zip 包文件,在弹出的功能框中使用
Copy path功能来拷贝文件地址; - 在
3.2. Unzip Dataset中,将拷贝的地址复制到zipfile_url输入框; - 点击该步骤的执行按钮,数据 zip 中的数据将会被解压到我们上面设置的
train_data_dir目录中(/content/LoRA/train_data),这些数据将会被用于后续的处理和训练。
到这里,我们就完成了训练数据的上传。
3.4、训练数据预处理
接下来,我们对上传的训练数据进行预处理,主要包括清理无用文件、图片打标等操作。我们来到 IV. Data Preprocessing。
首先,进行数据清理,主要是把一些训练不兼容的文件给清理掉或转换掉,如图:
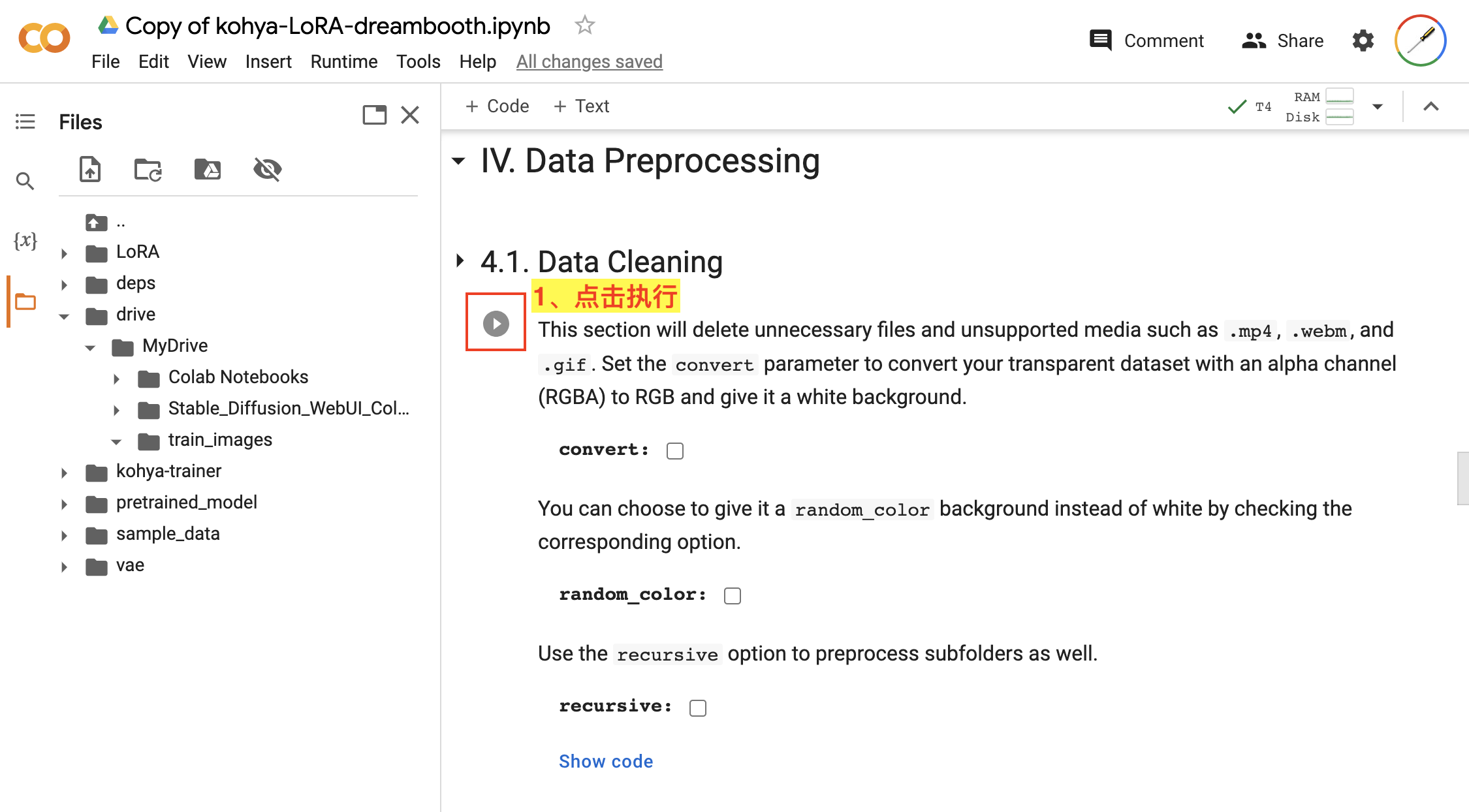
- 在
4.1. Data Cleaning步骤中,我们使用默认配置,直接点击该步骤的执行按钮即可。
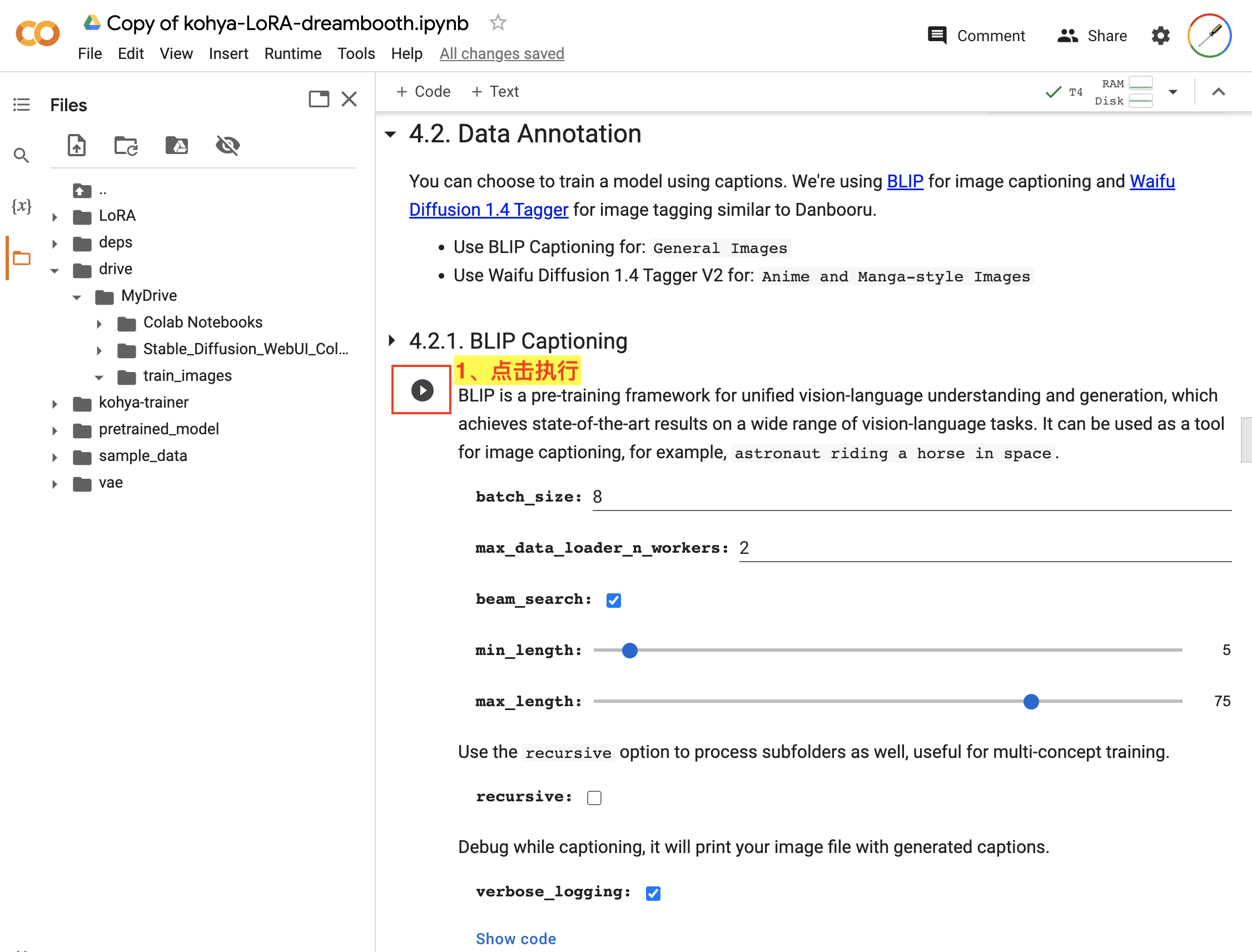
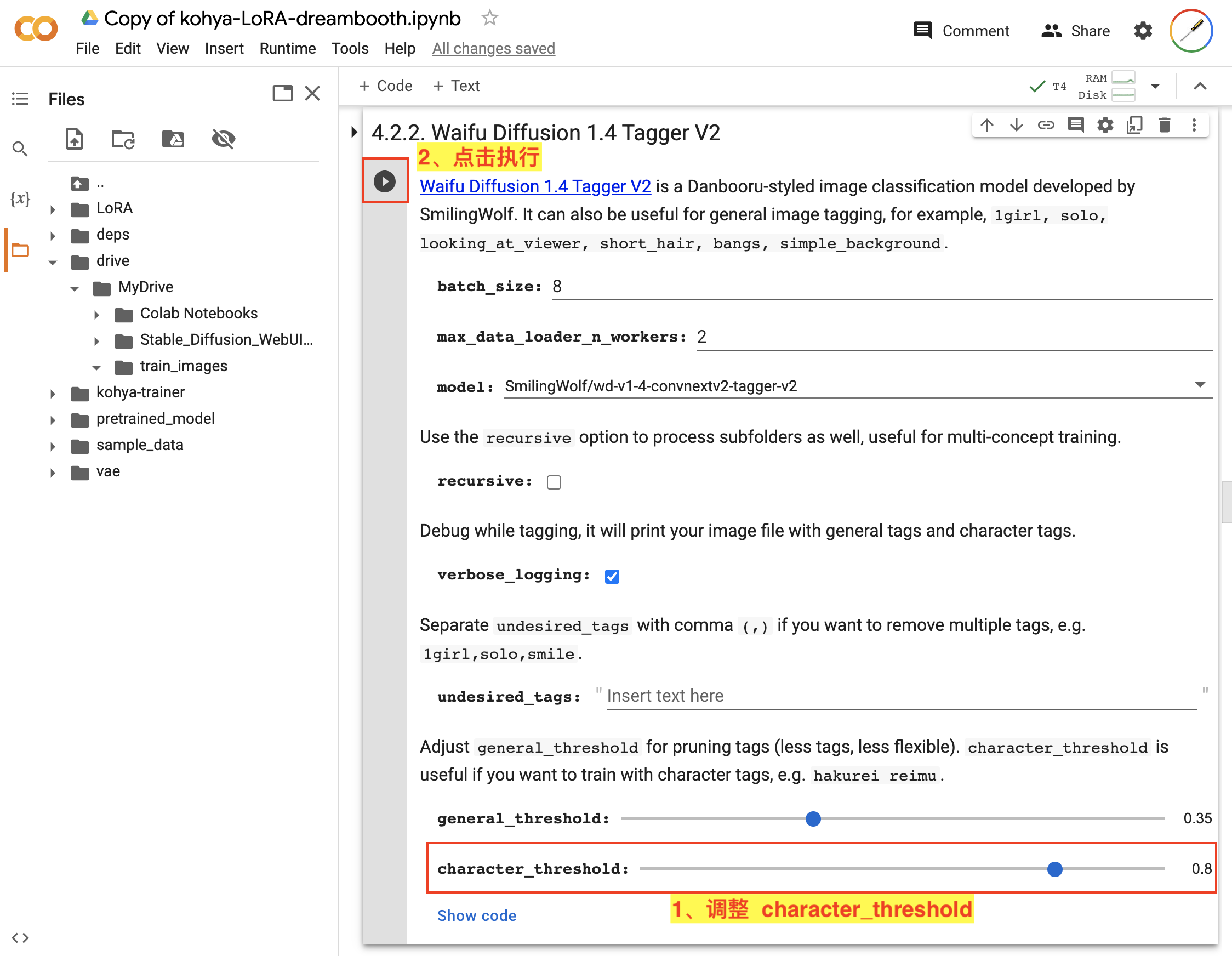
接着,在 4.2. Data Annotation 中对数据进行标注,其中包括使用 BLIP 对图像数据进行描述和使用 Waifu Diffusion 1.4 Tagger 对图像数据进行打标签。如图:
- 在
4.2.1. BLIP Captioning中使用默认配置,直接点击该步骤的执行按钮即可。 - 在
4.2.2. Waifu Diffusion 1.4 Tagger V2中,将character_threshold参数调高,然后点击该步骤的执行按钮即可。
3.5、训练模型
完成数据预处理,接下来就可以开始训练模型了。我们来到 V. Training Model。
首先,需要在 5.1. Model Config 设置一下模型的配置信息,如图:
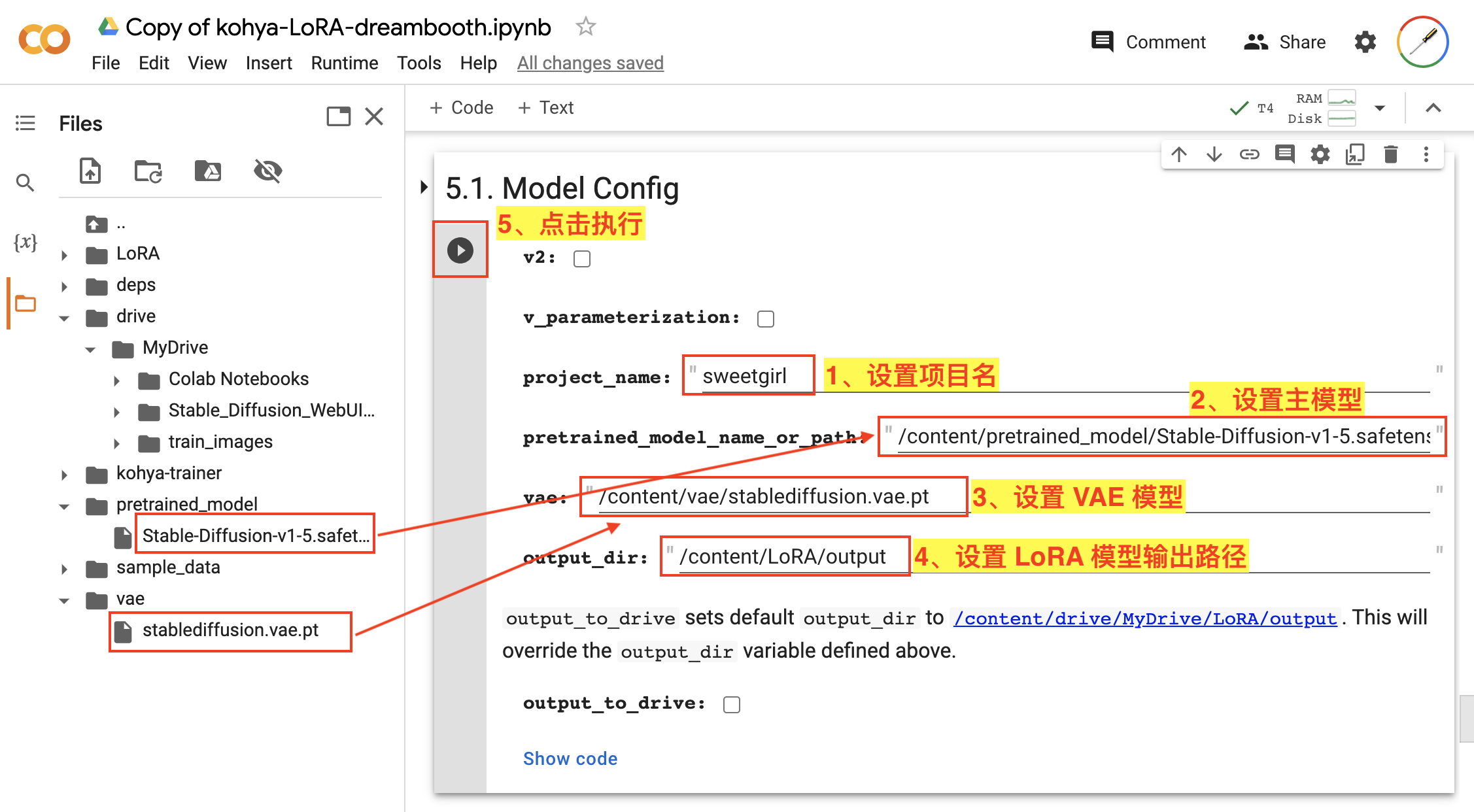
- 设置
project_name,这里对应的是输出的 LoRA 模型的名称,这里我们设置为sweetgirl; - 设置
pretrained_model_name_or_path,这里对应的是训练 LoRA 模型基于的主模型文件路径,这里我们就拷贝上面下载的Stable-Diffusion-v1-5.safetensors的路径; - 设置
vae,这里对应的是训练 LoRA 模型基于的 VAE 模型文件路径,这里我们就拷贝上面下载的stablediffusion.vae.pt的路径; - 设置
output_dir,这里是输出 LoRA 模型的路径,用默认值即可; - 点击该步骤的执行按钮。
接着,在 5.2. Dataset Config 设置数据集的配置信息,如图:
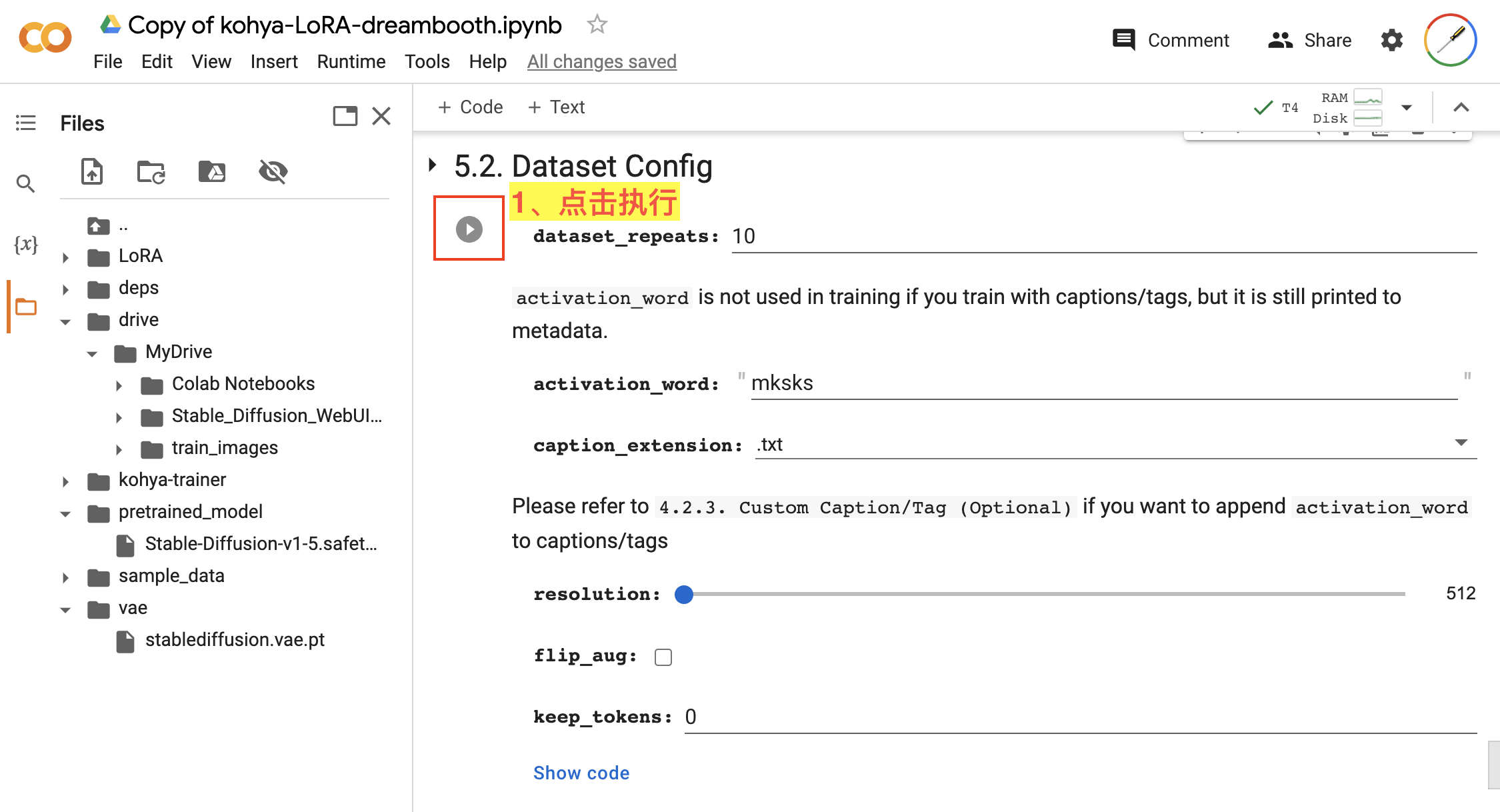
Dataset Config我们都使用默认配置参数,直接点击该步骤的执行按钮即可。
然后,在 5.3. LoRA and Optimizer Config 设置 LoRA 及优化器配置信息,如图:
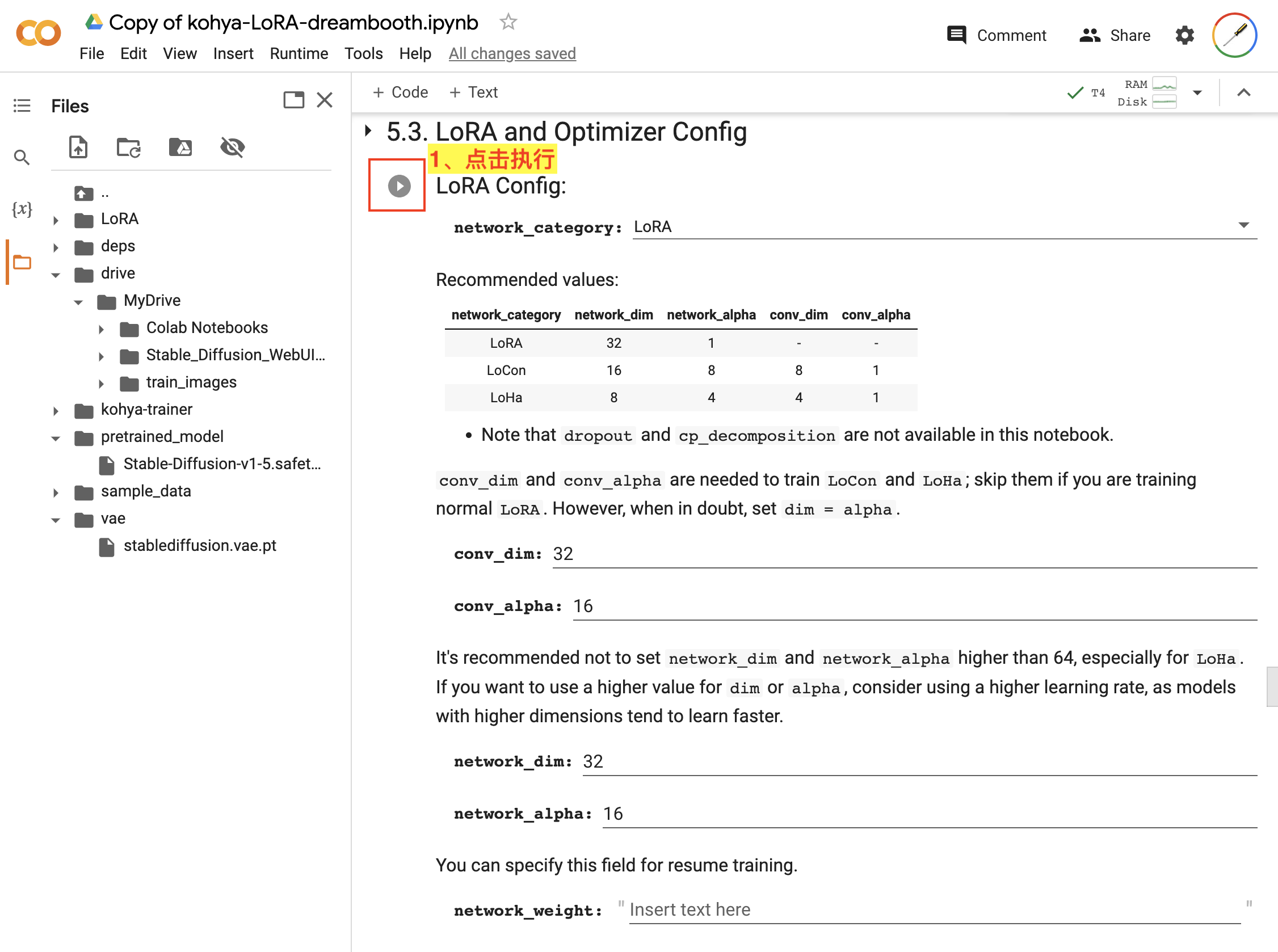
LoRA and Optimizer Config我们都使用默认配置参数,直接点击该步骤的执行按钮即可。
下一步,在 5.4. Training Config 设置训练过程相关的配置信息,如图:
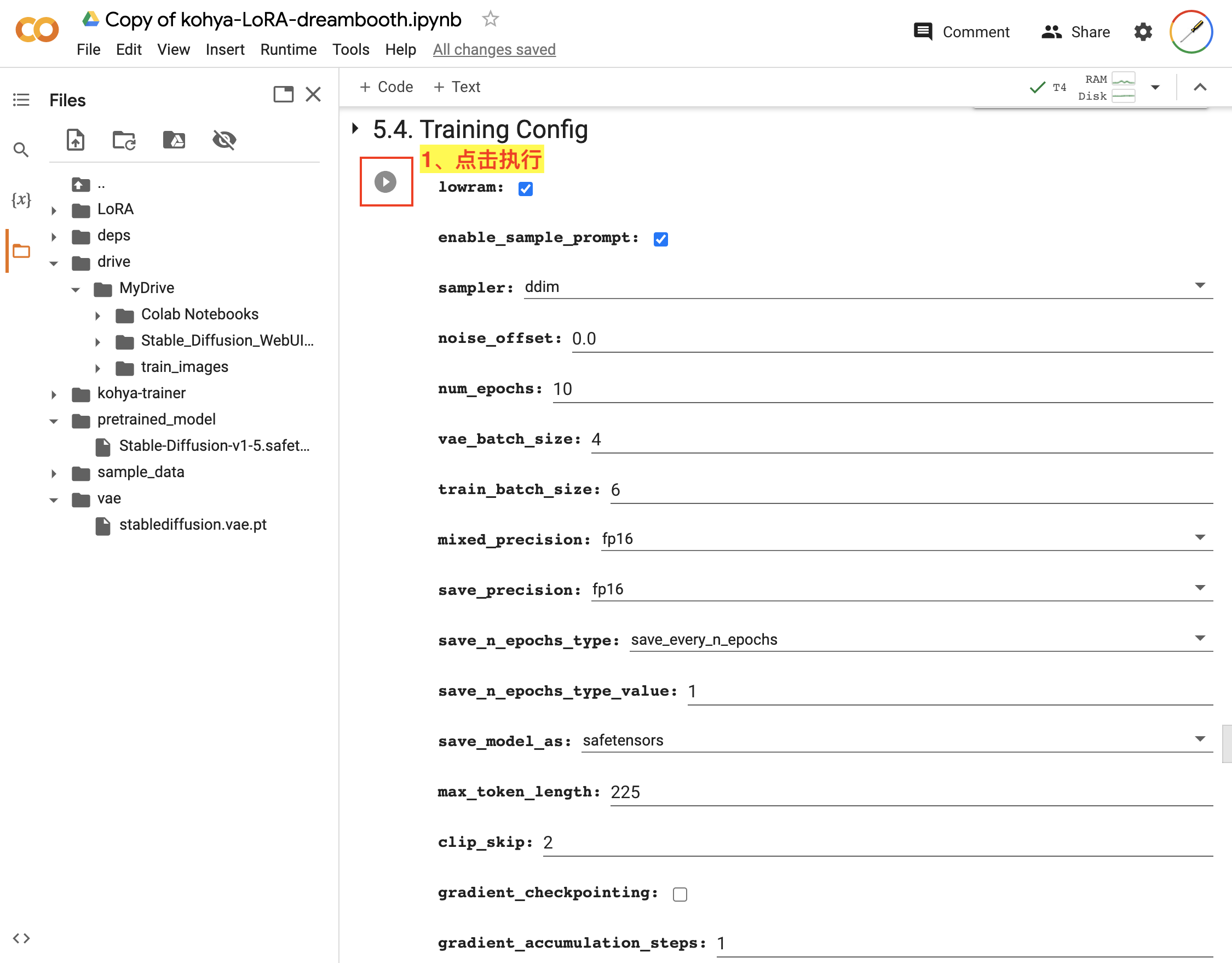
Training Config我们都使用默认配置参数,直接点击该步骤的执行按钮即可。
最后,在 5.5. Start Training 就可以开始训练 LoRA 模型的任务了,如图:
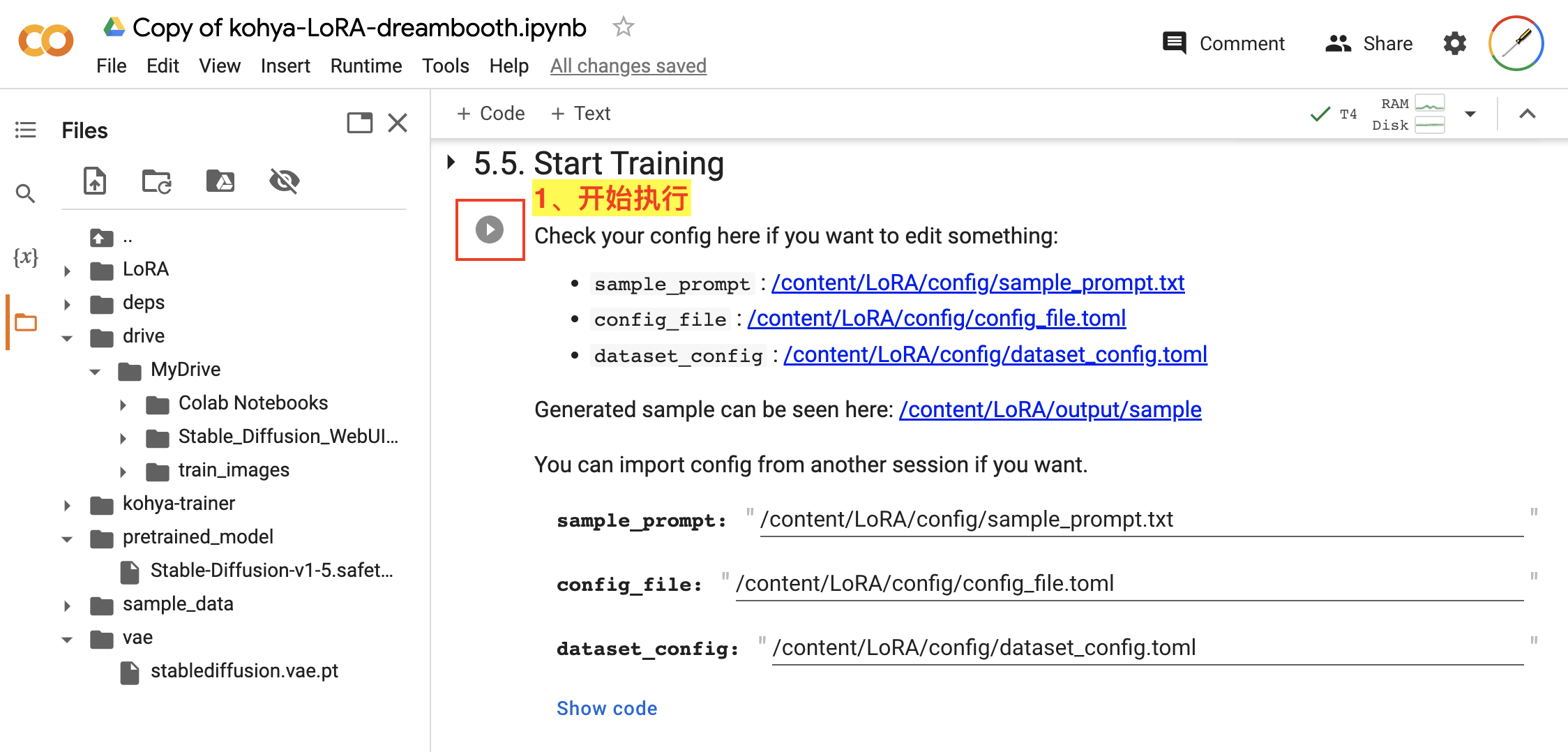
Start Training我们都使用默认配置参数,直接点击该步骤的执行按钮即可。
模型训练完成后,我们可以在输出路径找到模型文件,如图:
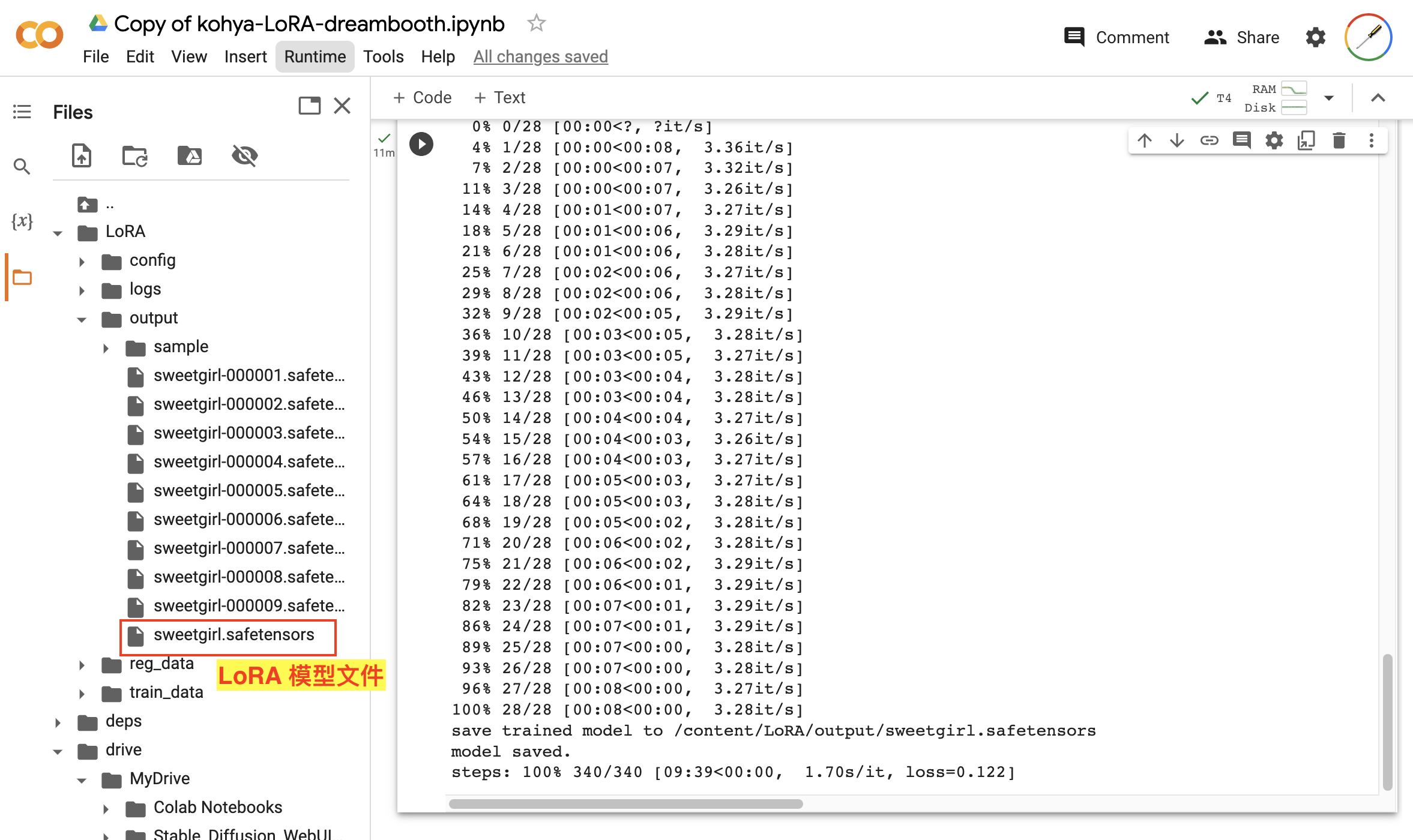
这样,我们就训练好了自己的 LoRA 模型。
4、测试 LoRA 模型
接下来我们可以在 Stable Diffusion WebUI 中来测试一下上面训练好的 LoRA 模型。
我们将训练好的模型文件 sweetgirl.safetensors 像其他 LoRA 模型一样拷贝到 stable-diffusion-webui/models/Lora 目录下,然后启动 WebUI。
接下来的测试流程跟使用其他 LoRA 模型一样,如图:
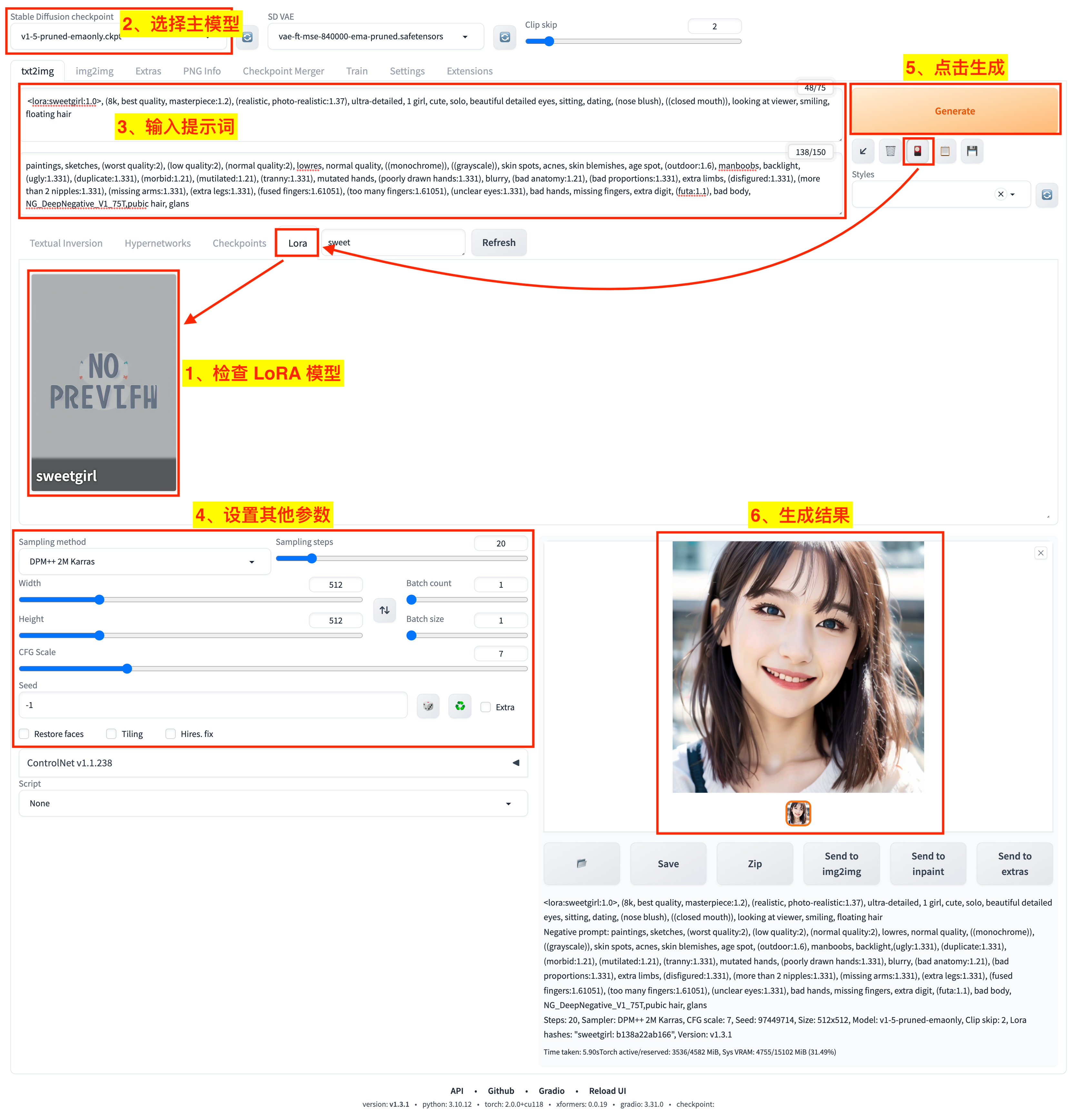
- 1)点击
Show/hide extra networks展示额外网络面板,选择Lora栏,检查是否成功加载了sweetgirl这个 LoRA 模型; - 2)选择主模型为 Stable Diffusion v1.5;
- 3)输入提示词和负向提示词,这里我们在提示词中添加了 LoRA 模型对应的标签 ` <lora:sweetgirl:1.0>`;
- 4)设置其他文生图参数;
- 5)点击
Generate按钮开始生成任务; - 6)等待生成结果。
下面是生成的结果:
