AI 教程:CLIP Skip 功能
CLIP(Contrastive Language-Image Pre-training)是用于将提示词文本转换为数字表示的神经网络模型。
向你推荐 FaceXSwap:On-Device Offline AI Face Swap for Free
在 iPhone 上直接对照片、GIF 动图、视频中的人脸实现快速换脸。无需上传任何数据,确保完全隐私与安全。即时、安全、无限次数、功能强大,现在即可免费试用。
在 AppStore 搜索 ‘facexswap’
- FaceXSwap 官网:https://facexswap.com
- FaceXSwap iOS App 下载:https://apps.apple.com/app/id6752116909
1、CLIP 和 CLIP Skip
CLIP(Contrastive Language-Image Pre-training)是用于将提示词文本转换为数字表示的神经网络模型。神经网络可以与这种数值表示进行很好的适配,因此 Stable Diffusion 的开发者选择将 CLIP 作为组成其 AI 绘图能力的重要模型之一。
既然 CLIP 是一个神经网络,那就意味着它有很多层,比如 Stable Diffusion 1.5 使用的 CLIP 模型一共有 12 层。我们输入的提示词首先会以一种简单的方式进行预处理,然后输入给神经网络。CLIP 神经网络的第一层将我们的提示词作为输入,并输出对应的数字表示,然后将数字表示输入给第二层。就这样,通过一层一层的处理和传输,直到 CLIP 的最后一层。最后得到的结果再输入给 Stable Diffusion 后续的模块。
CLIP 在逐层处理提示词的过程中,每一层都比上一层更细分、更具体。举个分层细分例子:比如在第 N 层是 person,那么在 N+1 层可能就细分为 male 和 female,如果在这一层选择了 female 的路径,那么到 N+2 层可能再细分为 woman、girl、lady、mother、grandma 等等。注意,这里并不是说 CLIP 模型就是这样的结构,只是概念上是类似的。
既然 CLIP 在逐层处理提示词的过程中会越来越细分和具体,那么最终的处理结果也就可能会出现过于细分而偏离我们预期的情况。比如,我们本来想画 a cat,而最终得到的 an Australian Mist 可能并不是我们想要的。这时候我们可能就希望能提前停止 CLIP 的分层处理过程,以防止提示词被过度细分处理,CLIP Skip就是用来实现这个功能的。
我们可以把 CLIP Skip 当做是设置 Stable Diffusion 文本模型对提示词处理准确度的一个参数。在实际使用中,我们可以遍历不同的数值从而找到一个符合我们预期的 CLIP Skip 数值。另外,需要注意的是 CLIP Skip 只在使用 CLIP 模型时才生效,在 Stable Diffusion 1.x 的版本及相关衍生模型,这个参数是有效的,但是在 Stable Diffusion 2.0 及相关衍生模型 CLIP Skip 是无效的,因为新版本里 Stable Diffusion 将 CLIP 模型换成了 OpenCLIP 模型。
2、在 Stable Diffusion WebUI 中使用 CLIP Skip
Stable Diffusion WebUI 中使用 CLIP Skip 可以如下图所示:
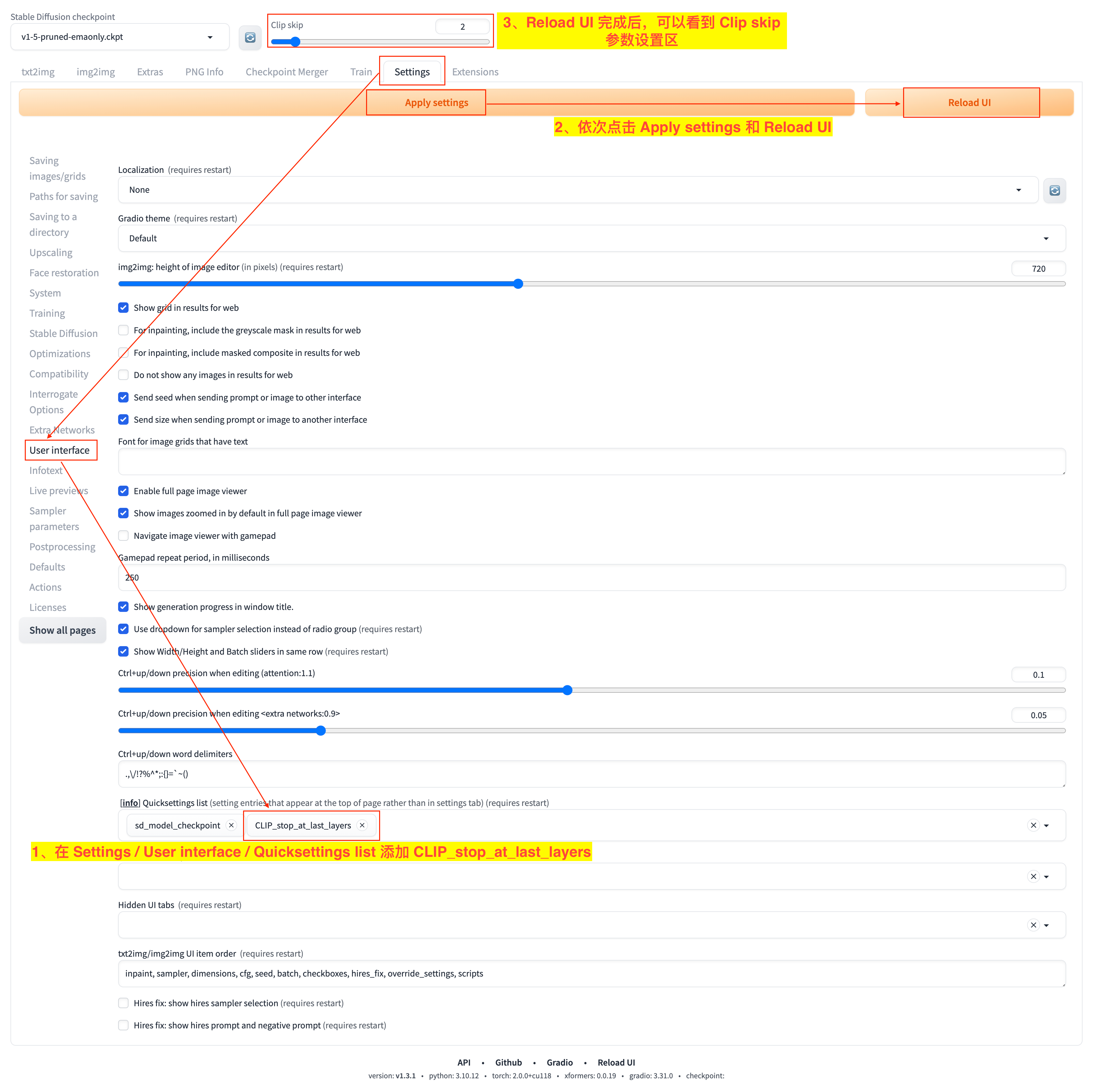
- 1)打开
Settings栏目的User interface边栏,在Quicksettings list下拉框添加CLIP_stop_at_last_layers选项; - 2)依次点击
Apply settings和Reload UI按钮来应用刚才的设置并重启 UI; - 3)重启 UI 完成后,就可以在页面上部看到
Clip skip参数的设置区了。
CLIP Skip 参数值设置为 1 时,表示会用到 CLIP 神经网络的所有层进行处理的结果,当 CLIP Skip 参数值设置为 2 时,表示会用到 CLIP 神经网络倒数第 2 层处理的结果,也就是跳过了最后一层,以此类推。
在我们使用 Stable Diffusion 1.5 模型时,CLIP Skip 参数的取值范围是 1-12,这是因为 Stable Diffusion 1.5 的 CLIP 神经网络一共有 12 层。
通常,我们一般设置 CLIP Skip 参数为 1 即可,即不跳过任何一层神经网络。但是针对一些使用 CLIP Skip 训练的微调模型,我们可以使用这个参数。