探索 Metal 音视频技术(5):计算命令编码器
本文将介绍 Metal 计算命令编码器。
想要学习和提升音视频技术的朋友,快来加入我们的【音视频技术社群】,加入后你就能:
- 1)下载 30+ 个开箱即用的「音视频及渲染 Demo 源代码」
- 2)下载包含 500+ 知识条目的完整版「音视频知识图谱」
- 3)下载包含 200+ 题目的完整版「音视频面试题集锦」
- 4)技术和职业发展咨询 100% 得到回答
- 5)获得简历优化建议和大厂内推
现在加入,送你一张 20 元优惠券:点击领取优惠券
微信扫码也可领取优惠券
这个系列文章我们来探索 Metal 音视频技术,对于想要开始学习音视频技术的朋友,这些文章是份不错的入门资料,本篇介绍如何创建并使用 MTLComputeCommandEncoder 对象来编码数据并行计算的状态与命令,并将它们提交到设备上执行。
执行一次数据并行计算,请遵循以下主要步骤:
- 使用
MTLDevice的方法创建一个计算管线状态(MTLComputePipelineState),其中包含来自MTLFunction对象的已编译代码,如“创建计算管线状态”中所述。MTLFunction对象表示用 Metal 着色语言编写的计算函数,详见“函数与库”。 - 指定计算命令编码器将要使用的
MTLComputePipelineState对象,如“为计算命令编码器指定计算状态与资源”中所述。 - 指定资源及相关对象(
MTLBuffer、MTLTexture以及可选的MTLSamplerState),这些对象可能包含要处理的数据以及计算状态要返回的结果。同时设置它们在参数表中的索引,以便 Metal 框架代码能在着色器代码中定位对应的资源。在任何时刻,MTLComputeCommandEncoder都可以关联多个资源对象。 - 按指定次数分派(dispatch)计算函数,如“执行计算命令”中所述。
1、创建计算管线状态
MTLFunction 对象代表一段可由 MTLComputePipelineState 对象执行的数据并行代码。MTLComputeCommandEncoder 对象编码用于设置参数并执行计算函数的命令。由于创建计算管线状态可能需要对 Metal 着色语言代码进行昂贵的编译操作,因此你可以使用同步或异步方法,以最适合你应用设计的方式来调度这项工作。
- 同步创建:调用
MTLDevice的newComputePipelineStateWithFunction:error:或newComputePipelineStateWithFunction:options:reflection:error:方法。这些方法会在 Metal 编译着色器代码以创建管线状态对象期间阻塞当前线程。 - 异步创建:调用
MTLDevice的newComputePipelineStateWithFunction:completionHandler:或newComputePipelineStateWithFunction:options:completionHandler:方法。这些方法会立即返回 —— Metal 将异步编译着色器代码以创建管线状态对象,然后在完成后调用你的完成处理器来提供新的MTLComputePipelineState对象。
在创建 MTLComputePipelineState对象时,你还可以选择创建反射数据(reflection data),这些数据揭示了计算函数及其参数的详细信息。newComputePipelineStateWithFunction:options:reflection:error:和 newComputePipelineStateWithFunction:options:completionHandler:方法会提供这些数据。若不会使用反射数据,请避免获取它们。有关如何分析反射数据的更多信息,请参见“在运行时确定函数详细信息”。
2、为计算命令编码器指定计算状态与资源
MTLComputeCommandEncoder对象的 setComputePipelineState:方法指定了用于一次数据并行计算通道的状态,其中包括已编译的计算着色器函数。在任何时刻,一个计算命令编码器只能关联一个计算函数。
以下 MTLComputeCommandEncoder方法指定了用作计算函数参数的资源(即缓冲区、纹理、采样器状态或线程组内存),该计算函数由 MTLComputePipelineState对象表示。
setBuffer:offset:atIndex:setBuffers:offsets:withRange:setTexture:atIndex:setTextures:withRange:setSamplerState:atIndex:setSamplerState:lodMinClamp:lodMaxClamp:atIndex:setSamplerStates:withRange:setSamplerStates:lodMinClamps:lodMaxClamps:withRange:setThreadgroupMemoryLength:atIndex:
每个方法将一个或多个资源分配给对应的参数,如图所示。
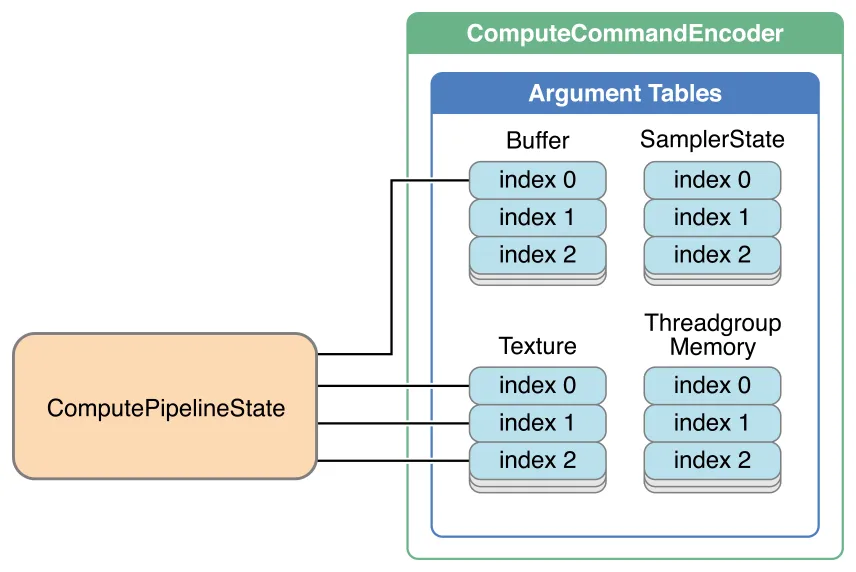 计算命令编码器的参数表
计算命令编码器的参数表
缓冲区、纹理或采样器状态参数表的最大条目数限制列于“实现限制”表中。线程组内存的最大总分配限制也列于“实现限制”表中。
3、执行计算命令
要编码执行计算函数的命令,请调用 MTLComputeCommandEncoder的 dispatchThreadgroups:threadsPerThreadgroup:方法,并指定线程组维度以及线程组的数量。你可以查询 MTLComputePipelineState的 threadExecutionWidth和 maxTotalThreadsPerThreadgroup属性,以在该设备上优化计算函数的执行。
线程组中的总线程数为 threadsPerThreadgroup各分量之积:
threadsPerThreadgroup.width * threadsPerThreadgroup.height * threadsPerThreadgroup.depth
maxTotalThreadsPerThreadgroup属性指定了在该设备上执行此计算函数时,单个线程组中可包含的最大线程数。
计算命令按它们被编码到命令缓冲区中的顺序执行。当与该命令关联的所有线程组完成执行且所有结果都已写入内存时,该计算命令才算完成执行。由于这种排序,计算命令的结果对命令缓冲区中其后编码的任何命令都可用。
要结束计算命令编码器的命令编码,请调用 MTLComputeCommandEncoder的 endEncoding方法。结束前一个命令编码器后,你可以创建任意类型的新命令编码器,以便将更多命令编码到命令缓冲区中。
4、代码示例:执行数据并行函数
清单 6-1展示了一个示例,该示例创建并使用 MTLComputeCommandEncoder对象,对指定数据执行图像变换的并行计算。(此示例未展示如何创建和初始化设备、库、命令队列以及资源对象。)该示例创建一个命令缓冲区,然后使用它来创建 MTLComputeCommandEncoder对象。接着创建了一个 MTLFunction对象,该对象表示从 MTLLibrary对象加载的入口点 filter_main,如清单 6-2 所示。然后使用该函数对象创建了名为 filterState的 MTLComputePipelineState对象。
该计算函数对图像 inputImage执行图像变换和过滤操作,结果返回到 outputImage中。首先,setTexture:atIndex:和 setBuffer:offset:atIndex:方法将纹理和缓冲区对象分配到指定参数表中的索引。paramsBuffer指定用于执行图像变换的值,inputTableData指定过滤器权重。计算函数以大小为 16×16 像素的二维线程组执行。dispatchThreadgroups:threadsPerThreadgroup:方法将执行计算函数的线程分派入队,endEncoding方法终止 MTLComputeCommandEncoder。最后,MTLCommandBuffer的 commit方法使命令尽快执行。
清单 6-1:在计算状态中指定并运行函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
id <MTLDevice> device;
id <MTLLibrary> library;
id <MTLCommandQueue> commandQueue;
id <MTLTexture> inputImage;
id <MTLTexture> outputImage;
id <MTLTexture> inputTableData;
id <MTLBuffer> paramsBuffer;
// ... 创建并初始化设备、库、队列、资源
// 获取新的命令缓冲区
id <MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer];
// 创建计算命令编码器
id <MTLComputeCommandEncoder> computeCE = [commandBuffer computeCommandEncoder];
NSError *errors;
id <MTLFunction> func = [library newFunctionWithName:@"filter_main"];
id <MTLComputePipelineState> filterState
= [device newComputePipelineStateWithFunction:func error:&errors];
[computeCE setComputePipelineState:filterState];
[computeCE setTexture:inputImage atIndex:0];
[computeCE setTexture:outputImage atIndex:1];
[computeCE setTexture:inputTableData atIndex:2];
[computeCE setBuffer:paramsBuffer offset:0 atIndex:0];
MTLSize threadsPerGroup = {16, 16, 1};
MTLSize numThreadgroups = {inputImage.width/threadsPerGroup.width,
inputImage.height/threadsPerGroup.height, 1};
[computeCE dispatchThreadgroups:numThreadgroups
threadsPerThreadgroup:threadsPerGroup];
[computeCE endEncoding];
// 提交命令缓冲区
[commandBuffer commit];
清单 6-2展示了上述示例对应的着色器代码。(函数 read_and_transform和 filter_table为用户定义的代码占位符)。
清单 6-2:着色语言计算函数声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
kernel void filter_main(
texture2d<float,access::read> inputImage [[ texture(0) ]],
texture2d<float,access::write> outputImage [[ texture(1) ]],
uint2 gid [[ thread_position_in_grid ]],
texture2d<float,access::sample> table [[ texture(2) ]],
constant Parameters* params [[ buffer(0) ]]
)
{
float2 p0 = static_cast<float2>(gid);
float3x3 transform = params->transform;
float4 dims = params->dims;
float4 v0 = read_and_transform(inputImage, p0, transform);
float4 v1 = filter_table(v0,table, dims);
outputImage.write(v1,gid);
}
本文转自微信公众号
关键帧Keyframe,推荐您关注来获取音视频、AI 领域的最新技术和产品信息:
微信扫码关注我们
你还可以加入我们的微信群和更多同行朋友来交流和讨论:
微信扫码进群