AI 教程:配置 Stable Diffusion 相关模型
我们可以使用很多其他的模型来进行不同细分方向的 AI 绘画,我们这篇内容就来介绍一下这些模型的区别,以及如何在 WebUI 中使用它们。
向你推荐 FaceXSwap:On-Device Offline AI Face Swap for Free
在 iPhone 上直接对照片、GIF 动图、视频中的人脸实现快速换脸。无需上传任何数据,确保完全隐私与安全。即时、安全、无限次数、功能强大,现在即可免费试用。
在 AppStore 搜索 ‘facexswap’
- FaceXSwap 官网:https://facexswap.com
- FaceXSwap iOS App 下载:https://apps.apple.com/app/id6752116909
在前面我们介绍了基于 Stable Diffusion 基础模型进行 AI 绘画的相关功能,其实在 WebUI 中我们还可以使用很多其他的模型来进行不同细分方向的 AI 绘画,我们这篇内容就来介绍一下这些模型的区别,以及如何在 WebUI 中使用它们。
1、Stable Diffusion 相关模型介绍
在我们使用 Stable Diffusion WebUI 进行 AI 绘画时,除了前面介绍过的 Stable Diffusion 基础模型外,我们还可能会接触到这些类型的模型:
- Checkpoint 模型
- VAE 模型
- Embedding(Textual Inversion) 模型
- Hypernetwork 模型
- LoRA 模型
- Aesthetic Gradient 模型
- LyCORIS 模型
- ControlNet 模型
通常这些模型的文件格式有这样几种:
.ckpt:Pytorch 的标准模型格式,可以嵌入 python 代码,容易受攻击。.pt:Pytorch 的标准模型格式,可以嵌入 python 代码,容易受攻击。.pth:Pytorch 的标准模型格式,可以嵌入 python 代码,容易受攻击。.safetensor:只包含模型需要的数据,不包含 python 代码,可与其他格式的 Pytorch 模型进行格式转换,数据内容无区别。是更安全的一种模型格式。一般有.safetensor格式的,尽量选用改格式。
这么多类型的模型是随着技术发展逐渐衍生出来的,其中,Checkpoint 模型是在 Stable Diffusion 基础模型上微调后替代其成为基础模型,其他模型则大多是配合基础模型一起工作的扩展类模型,它们一般不独立使用,而是在作为基础模型的插件来工作。这些模型在我们使用 Stable Diffusion 进行 AI 绘画的过程中会起到不同的作用,下面我们来逐一介绍一下它们。
1.1、Checkpoint 模型
我们在前文中介绍过 Stable Diffusion 基础模型,它具有较好的通用基础能力,但是当我们需要用它来画出特定的风格时,它可能离我们的预期还有一定的距离,这时候就可以在 Stable Diffusion 基础模型上微调来获得具有特定风格微调模型。Checkpoint 模型就是满足这种特定需求的一种选择。
Checkpoint 从字面上理解,是『检查点』的意思,这个概念很像我们玩游戏时的存档功能,也就是将游戏保存到当前的状态,这样一来,即使游戏失败,也不用重新开始玩,从上一次的存档位置开始即可。
在 AI 模型训练时,也有类似的情况。一般来讲,训练 AI 模型的过程都是耗时较长的,如果缺乏一定的可靠性机制,过程中一旦失败,就需要重头开始训练,这样会浪费很多时间,尤其是对于训练大模型,是几乎不可接受的。因此,就需要实现类似游戏存档的机制来保证可靠性,这种机制就被称为『检查点(Checkpoint)』模式。
Checkpoint 模型就是使用检查点模式,在上面讲到的 Stable Diffusion 模型基础上做 Fine-Tune 而来。Fine-Tune 的过程通常就是在前面模型状态(Checkpoint)的基础上进行调优,这样可以更好的针对新数据进行训练,从而获得我们需要的风格。
对于 Stable Diffusion 来讲 Checkpoint 模型是基础模型,也称为主模型。一个 Checkpoint 模型中包含了图像生成任务中所有必需的信息,它决定了 AI 绘画的整体风格,所以只要有 Checkpoint 模型就能完成 AI 绘画的任务。正因为如此,Checkpoint 模型文件通常也比较大,一般在 GB 级别。
我们上面讲到,从头训练得到 Stable Diffusion 原模型是成本很高的,相比而言,Checkpoint 模型在 Stable Diffusion 基础模型上进一步训练调优而来,成本就降低很多了。
虽然 Checkpoint 模型已经可以用比较低的成本来满足一些特定需求,但是一个 Checkpoint 模型通常只能满足某一类或某几类需求,对于更加细分的需求,Checkpoint 模型在细节、精准度、灵活性上可能还是会不符合预期,这就需要更加垂直的技术方案。
1.2、VAE 模型
VAE 的全称是变分自动编码器 (Variational Auto-Encoder),是由 Diederik P. Kingma 和 Max Welling 在论文《Auto-Encoding Variational Bayes》提出的一种人工神经网络结构。
和 Stable Diffusion 搭配使用时,VAE 模型是在主模型的基础上做微调的,它的效果类似于我们熟悉的滤镜,可以调整生成图片的色彩饱和度。
1.3、Embedding(Textual Inversion) 模型
Textual Inversion 就是一种垂直的 Fine-Tune 微调技术。这个技术由 Rinon Gal 等人在论文 《An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion》 中提出,并将项目开源在了 https://github.com/rinongal/textual_inversion。
在我们使用提示词来进行 AI 绘画时,为了准确稳定的画出我们预期的角色、物品、行为或者画风,我们通常需要输入比较多的提示词去描述和限定它,对提示词的运用需要积累一定的经验才能掌握的更好。有没有什么技术可以让我们通过简短的提示词就固定下对某些特定对象的描述呢?Textual Inversion 就是一种解决方案。
Textual Inversion 是一种从少量示例图像中捕捉新概念的技术,可以用于控制文本到图像的管线。它的思路是在文本编码器(Text Encoder)的 Embedding 空间来学习新的『单词』来实现这一点。随后,在使用文本提示词进行 AI 绘画时,可以使用这些『单词』来实现对结果图像的精细控制。简单来讲,就是把一堆提示词描述所能达到的效果打包成一个特殊提示词来完成。
Embedding 模型是使用 Textual Inversion 技术训练产生的结果。由于它只负责文本理解的模块,训练过程不会对 Stable Diffusion 模型产生改动,所以训练成本低、速度快,产生的结果文件也很小,通常在几十或上百 KB 级别。
Textual Inversion 工作原理:
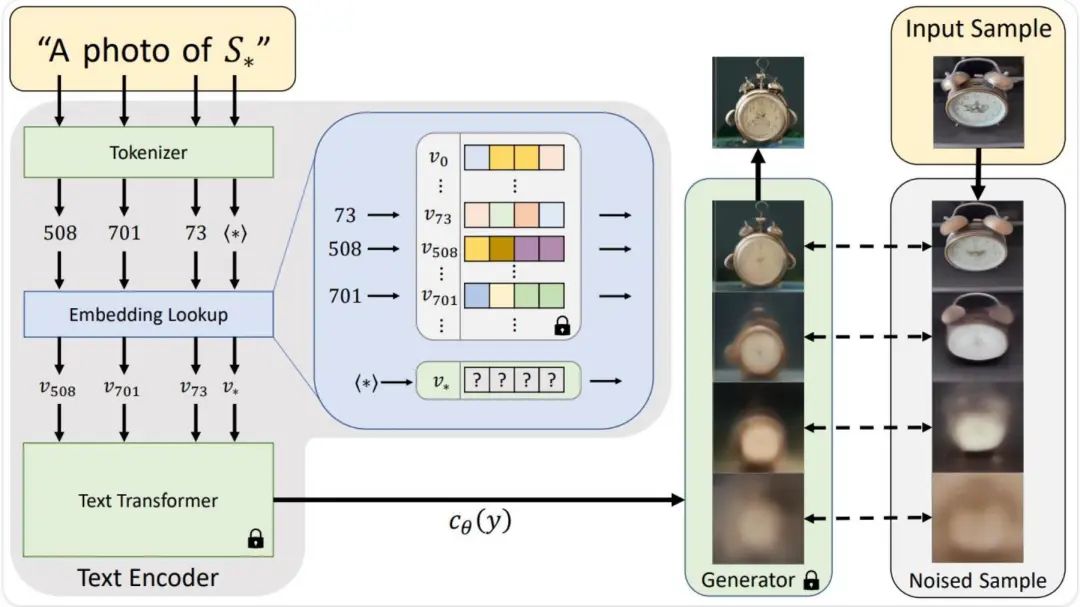
Textual Inversion 效果示例:

1.4、Hypernetwork 模型
Hypernetwork 模型是另一种解决垂直需求的方案。
Hypernetwork 最初是 NovelAI 研发人员的提出的一种大模型微调技术。参考:《NovelAI Improvements on Stable Diffusion》。
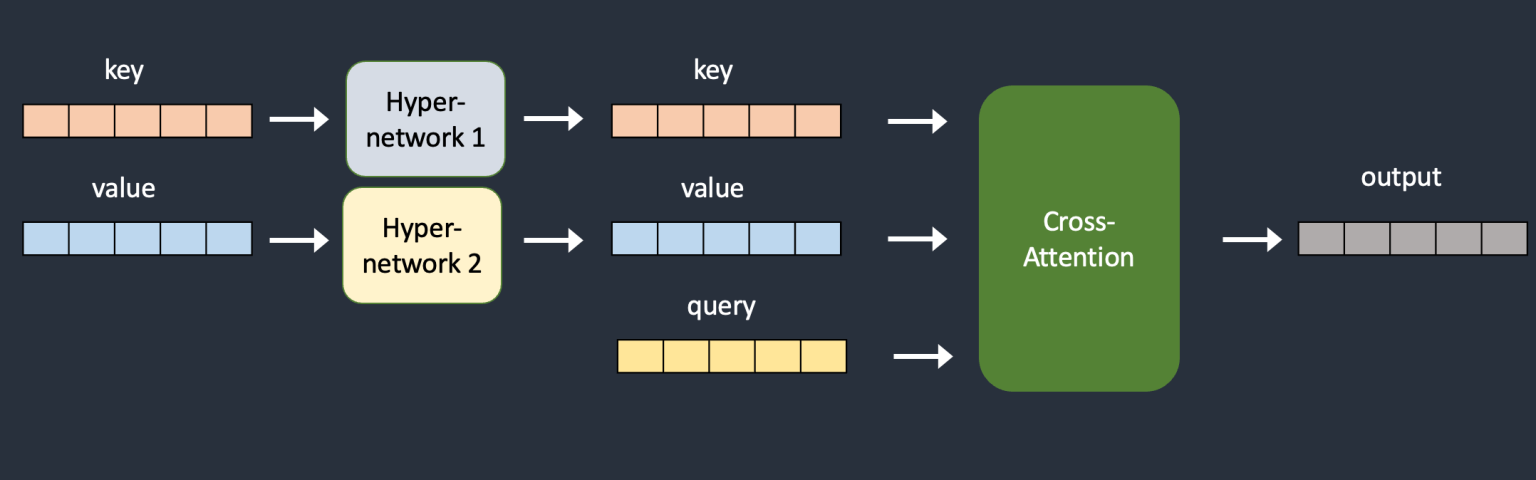
如前文介绍,Stable Diffusion 使用的扩散模型的扩散过程就是一个从图像噪声中降噪来生成图像的过程,Hypernetwork 的思路是在扩散过程中的每一步都通过一个额外的小网络来调整降噪的结果,从而影响 Stable Diffusion 的画风。
在训练 Hypernetwork 模型的过程中,Stable Diffusion 模型是锁定起来无法改变的,但是附加的网络是可以改变的,训练过程只需要有限的资源,并且速度非常快,在普通的计算机就可以完成。Hypernetwork 模型文件通常比较小,一般在几十到数百 MB 级别。
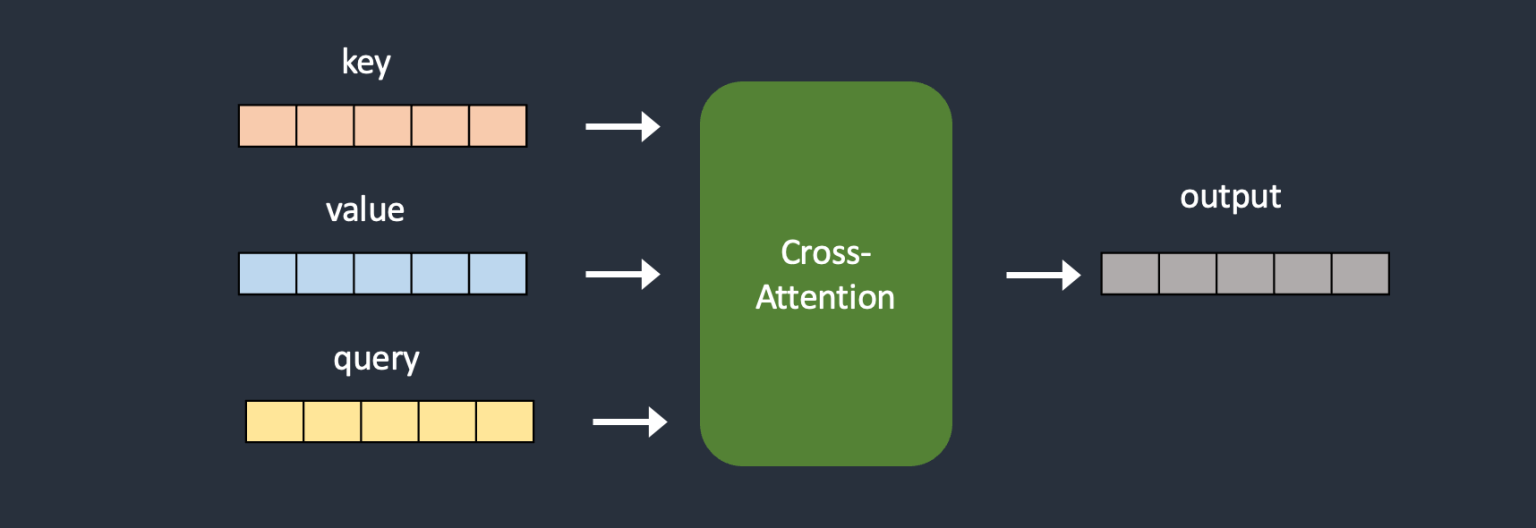
我们通过下面两张图可以很直观看到这个过程:
下图是原始 Stable Diffusion 模型的 Cross-Attention 模块:
下图是 Hypernetwork 在键值转换中注入了额外的神经网络:
1.5、LoRA 模型
LoRA 的全称是 Low-Rank Adaptation of Large Language Models,是微软研究院引入的一项用于处理大模型微调的技术。参考论文:《LoRA: Low-Rank Adaptation of Large Language Models》。
LoRA 本来是给大语言模型准备的,Simo Ryu 则提出了适用于 Stable Diffusion 的 LoRA 实现,并将项目开源在了 https://github.com/cloneofsimo/lora。
这样一来,使得使用自定义数据集来微调 Stable Diffusion 模型变得非常容易且成本很低。并且,使用 LoRA 可以支持发布单个较小的文件来让别人使用你的微调模型。这些优势成为了 LoRA 模型流行起来的基础。LoRA 模型文件大小一般在几 MB 到数百 MB 级别。
LoRA 对大模型的微调方式跟 Hypernetwork 很类似,它们都是通过改变 Stable Diffusion 的交叉注意层(Cross-Attention Layers)实现微调,不同之处在于它们改变的方式:LoRA 是改变交叉 Cross-Attention 的权重,Hypernetwork 则是嵌入额外的神经网络。用户们普遍发现 LoRA 模型能产生更好的效果,它不仅能用于画风,还可以用于动作、特定对象、角色等其他特定概念。
1.6、Aesthetic Gradient 模型
美学梯度(Aesthetic Gradients)也是对 Stable Diffusion 模型进行微调的一种方案,它可以实现图像生成风格的自定义,创建独特的美学风格。
该方案由 Victor Gallego 在论文 《Personalizing Text-to-Image Generation via Aesthetic Gradients》 中提出,并在 https://github.com/vicgalle/stable-diffusion-aesthetic-gradients 开源了该项目。
美学梯度(Aesthetic Gradients)模型的思路是通过微调 CLIP 文本编码器(Text Encoder)将文本编码输出表示由原特征空间 A 投影到另外的『美学』特征空间 B,进而在 Diffusion 去噪过程中,逐步生成具备该『美学』风格的图像。
由于这种特征空间的转换是在微调时通过控制CLIP 文本编码器(Text Encoder)训练时的梯度朝着『美学』风格方向收敛,所以该方案命名为美学梯度(Aesthetic Gradients)模型定制化方案。
不过现在美学梯度模型已经是比较落后的模型方案了,效果相对于其他方案比较差,且大模型可能已经集成它的算法,用的人不多。
1.7、LyCORIS 模型
LyCORIS 的全称是 Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion,是一个类似 LoRA 的微调方案。它实现了不同算法来对 Stable Diffusion 进行高效的参数微调。
该项目开源在 https://github.com/KohakuBlueleaf/LyCORIS。
LyCORIS 在 LoRA 的基础上做了一些算法和技术实现的优化,比如:LoCon(LoRA for Convolution Network)和 LoHa(LoRA with Hadamard)等优化方案。LoCon 在 LoRA 的基础上通过矩阵乘法降阶矩阵来降低参数的量,LoHa 则在 LoRA 的基础上通过哈达马积进一步降低参数的量,预期比 LoRA 获得更好的微调效果。
因此,LyCORIS 模型也分为 LoCon 模型和 LoHA 模型。和 LoRA 模型类似,LyCORIS(LoCon/LoHa)模型 模型文件大小一般在几 MB 到几百 MB。
1.8、ControlNet 模型
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。它提供了一种增强稳定扩散的方法,在文本到图像生成过程中使用条件输入(如边缘映射、姿势识别等),可以让生成的图像将更接近输入图像,这比传统的图像到图像生成方法有了很大的改进。
在 Stable Diffusion 的基础上使用 ControlNet 就相当于给 Stable Diffusion 加了一个插件用于提供更精细的生成控制。对于控制生成图的姿态、线条、结构、深度等方面有非常惊艳的效果。
该项目开源在 https://github.com/lllyasviel/ControlNet。
其中用于集成到 Stable Diffusion WebUI 的 ControlNet 插件项目则开源在 https://github.com/Mikubill/sd-webui-controlnet。
ControlNet 模型根据其使用的算法可分为不同的模型,比如:用于精细线稿控制的 Canny 模型、用于柔和线稿控制的 HED 模型、用于涂鸦成图控制的 Scribble 模型、用于区块上色控制的 Seg 模型、用于骨骼绑定控制的 OpenPose 模型等等。这些模型一般大小从几百 MB 到几 GB 级别。
2、配置 Stable Diffusion 相关模型
接下来我们先来介绍一下怎么在 WebUI 项目中去配置 Stable Diffusion 相关模型。
2.1、Stable Diffusion WebUI 模型和扩展的配置路径
Stable Diffusion WebUI 项目专门留出了固定目录来给大家配置自己要用的模型及扩展。
各种模型配置的目录主要有这些:
stable-diffusion-webui/models/Stable-diffusion:这个目录下可以配置原版的 Stable Diffusion 基础模型,以及微调过的Checkpoint 模型。配置方式就是直接把下载下来的模型文件拷贝过来即可。stable-diffusion-webui/models/VAE:这个目录下可以配置VAE 模型。配置方式也是拷贝模型文件即可。stable-diffusion-webui/embeddings:这个目录下可以配置Embedding(Textual Inversion) 模型。配置方式也是拷贝模型文件即可。stable-diffusion-webui/models/hypernetworks:默认可能没有 hypernetworks 这个目录,需要自己创建。这个目录下可以配置Hypernetwork 模型。配置方式也是拷贝模型文件即可。stable-diffusion-webui/models/Lora:默认可能没有 Lora 这个目录,需要自己创建。这个目录下可以配置LoRA 模型。配置方式也是拷贝模型文件即可。
各种扩展配置的目录主要在:
stable-diffusion-webui/extensions:这个目录下可以安装各种扩展插件。配置方式一般是把对应的扩展项目拷贝过来或者把 git 项目克隆过来。我们前面提到的Aesthetic Gradient 模型、LyCORIS 模型、ControlNet 模型在 WebUI 中都是通过扩展的方式来配置使用的,这个我们在下一篇内容详细介绍。
2.2、Stable Diffusion WebUI 模型配置示例
在实际应用中,我们最常用到的模型是 Checkpoint 模型和 LoRA 模型,偶尔也需要配置一下 VAE 模型,我们就以这几种模型为例来介绍一下配置流程。
1)模型下载:模型发现和下载站点
在配置模型之前,我们通常需要先挑选和下载模型,这里给大家推荐几个常用的模型下载站点:
- Civitai(https://civitai.com/):一个 AI 艺术绘画模型资源分享和发现的平台。
- HuggingFace(https://huggingface.co/):一个用户共享机器学习模型和数据集的平台。
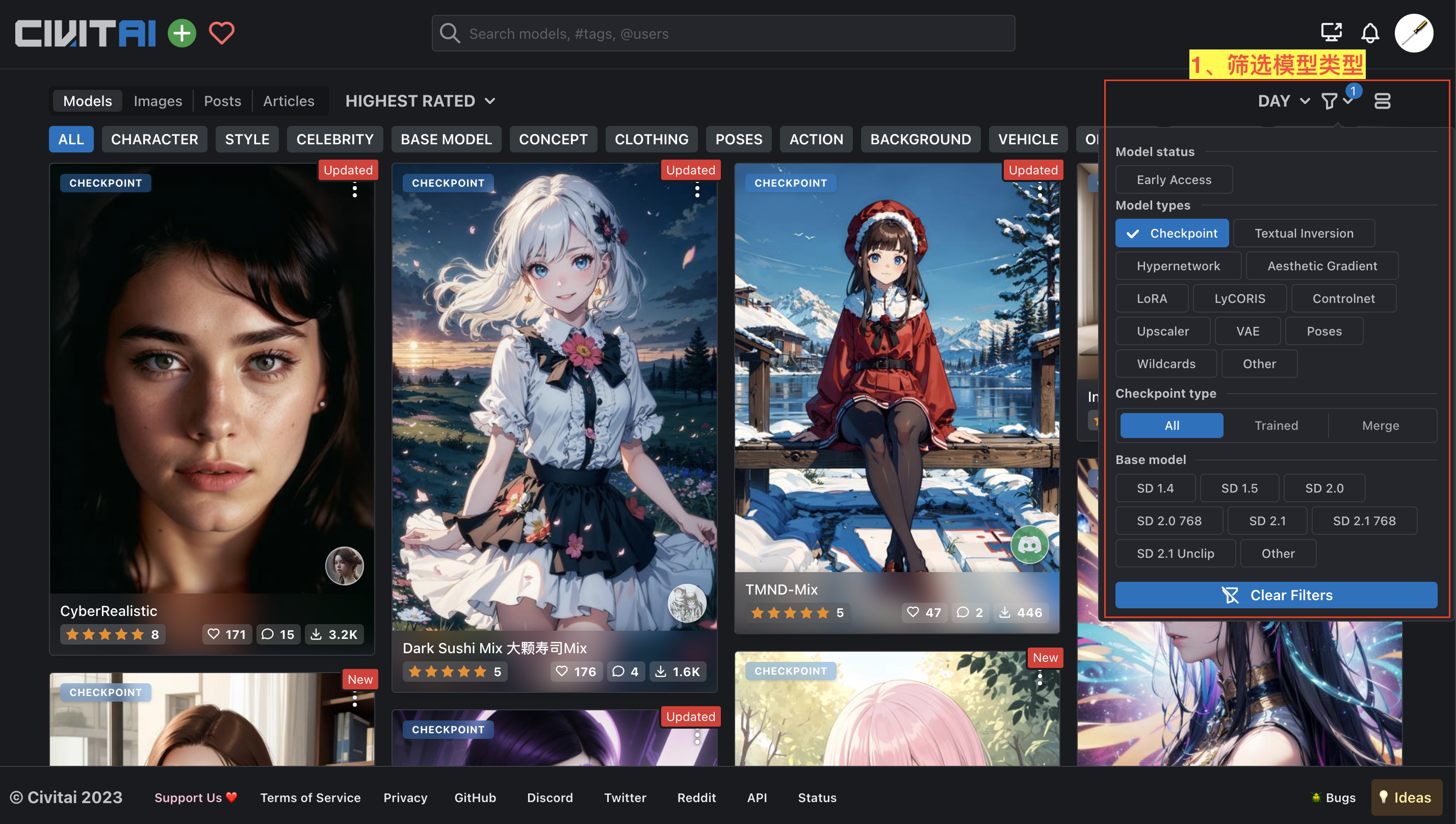
Civitai 是比较适合我们去寻找想要模型的站点,它把各种模型做了分类,并且有很多对应模型生成图的展示,如下图所示:
如果因为网络问题无法访问 Civitai,国内也有一些类似的替代站点可以使用:
- 哩布哩布 AI:(https://www.liblibai.com/)
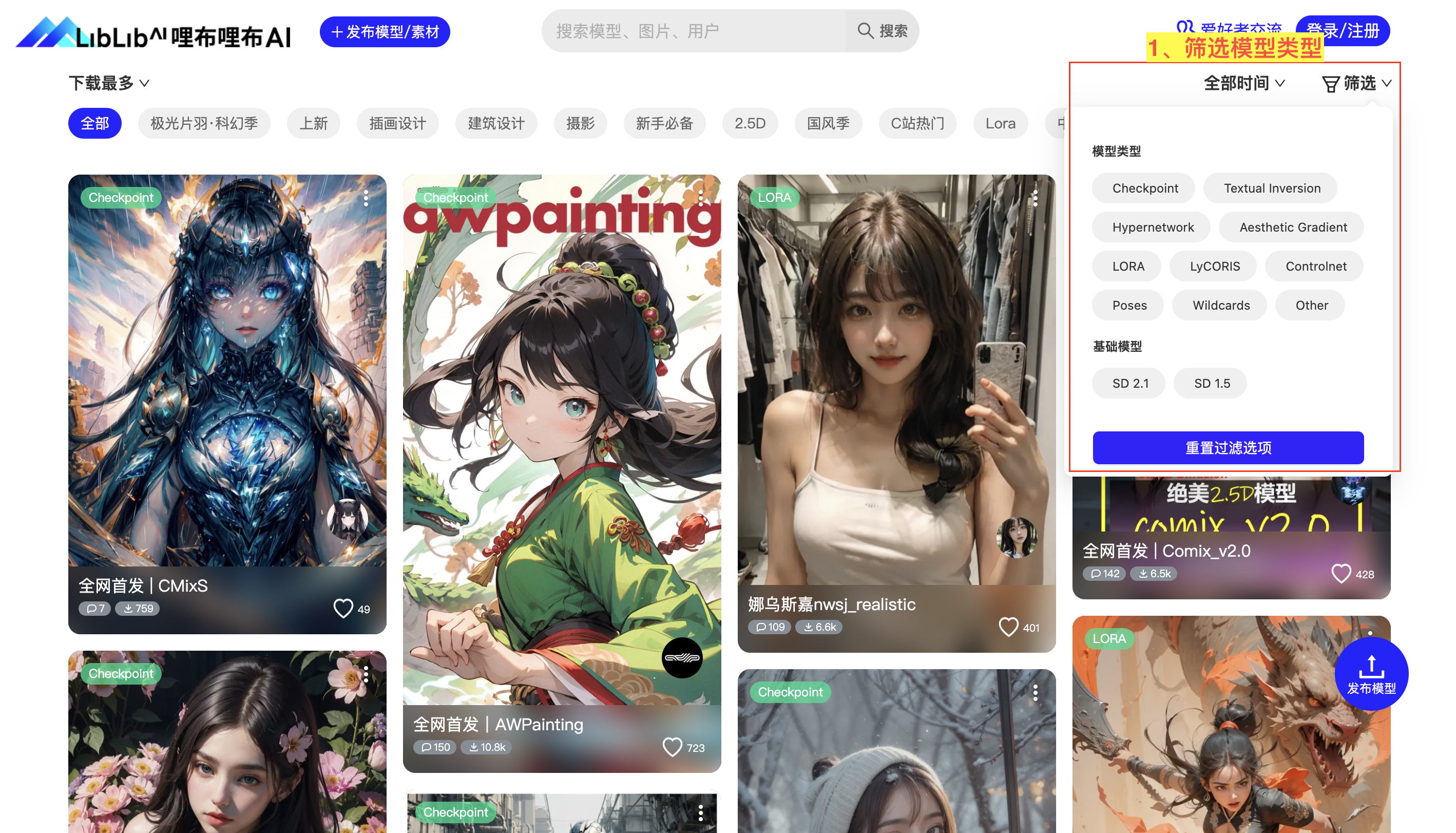
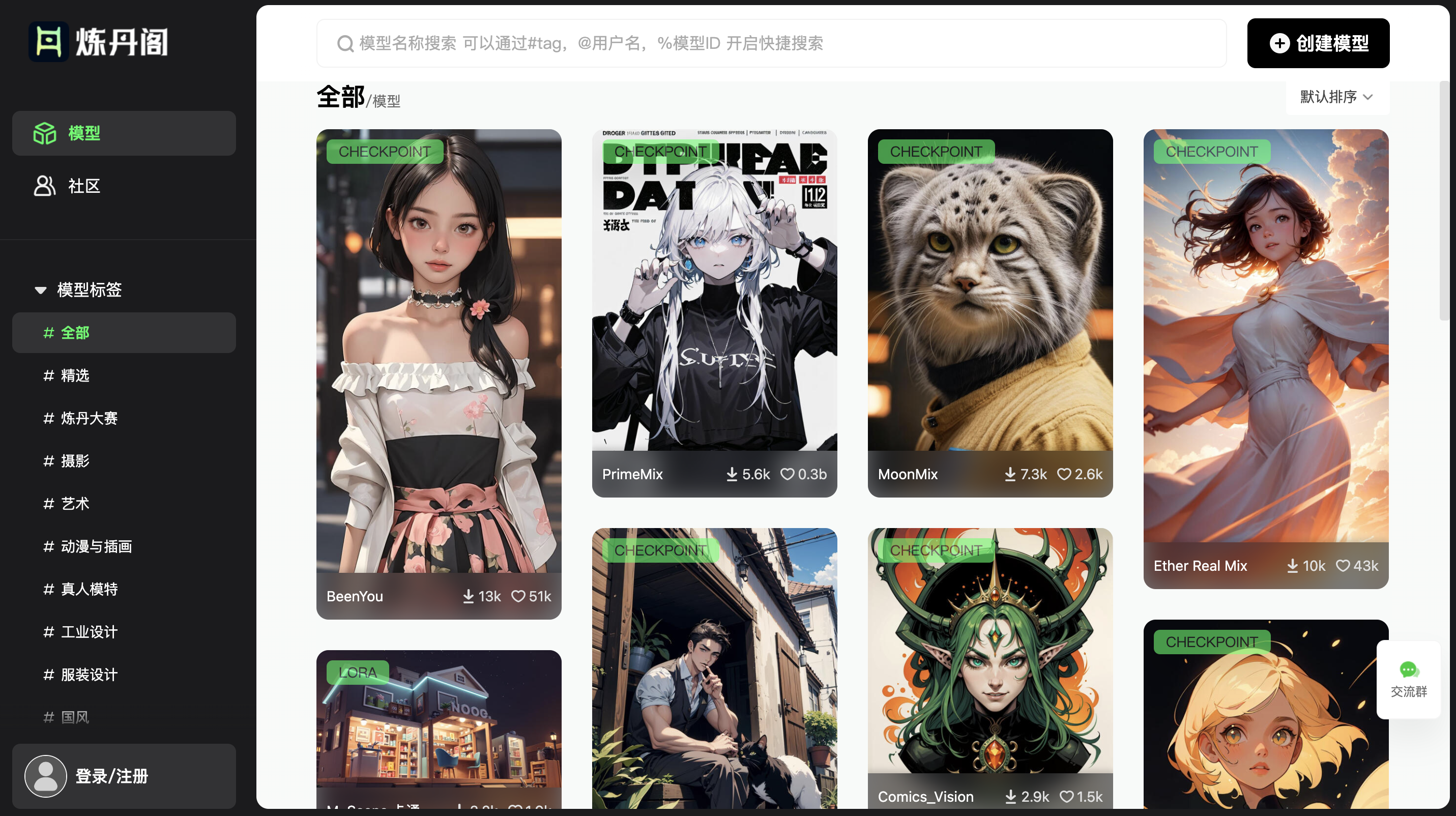
2)模型配置:配置 Checkpoint 模型并测试模型效果
我们这里在哩布哩布 AI 分别挑选一个 Checkpoint 主模型:明快 CrispMix(https://www.liblibai.com/#/model/691)。如图:
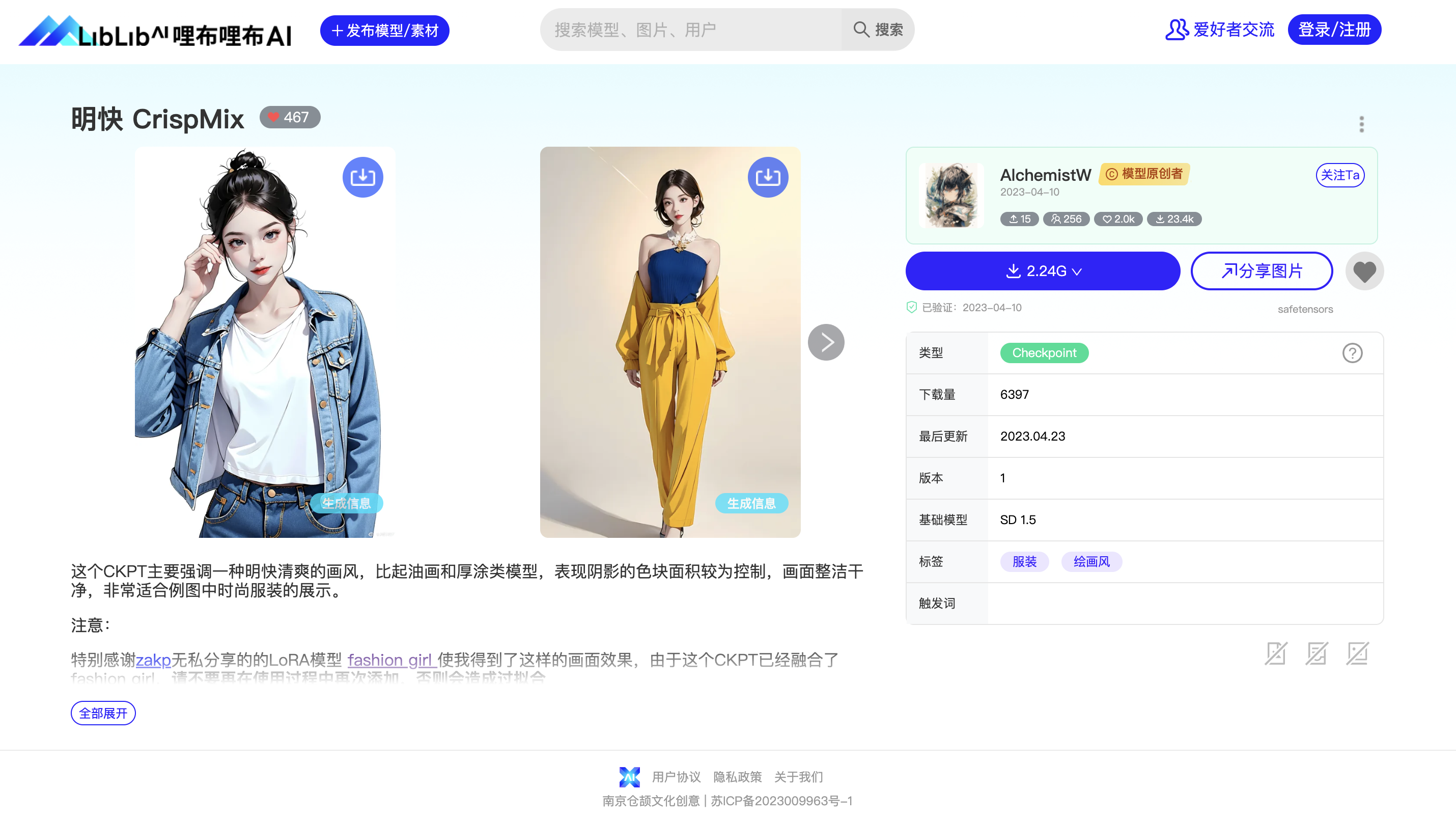
在模型信息页面点击下载按钮把模型文件下载下来,然后我们把『明快 CrispMix』这个 Checkpoint 主模型文件拷贝到 stable-diffusion-webui/models/Stable-diffusion 目录下。
接下来,我们启动 WebUI 来测试模型配置效果。
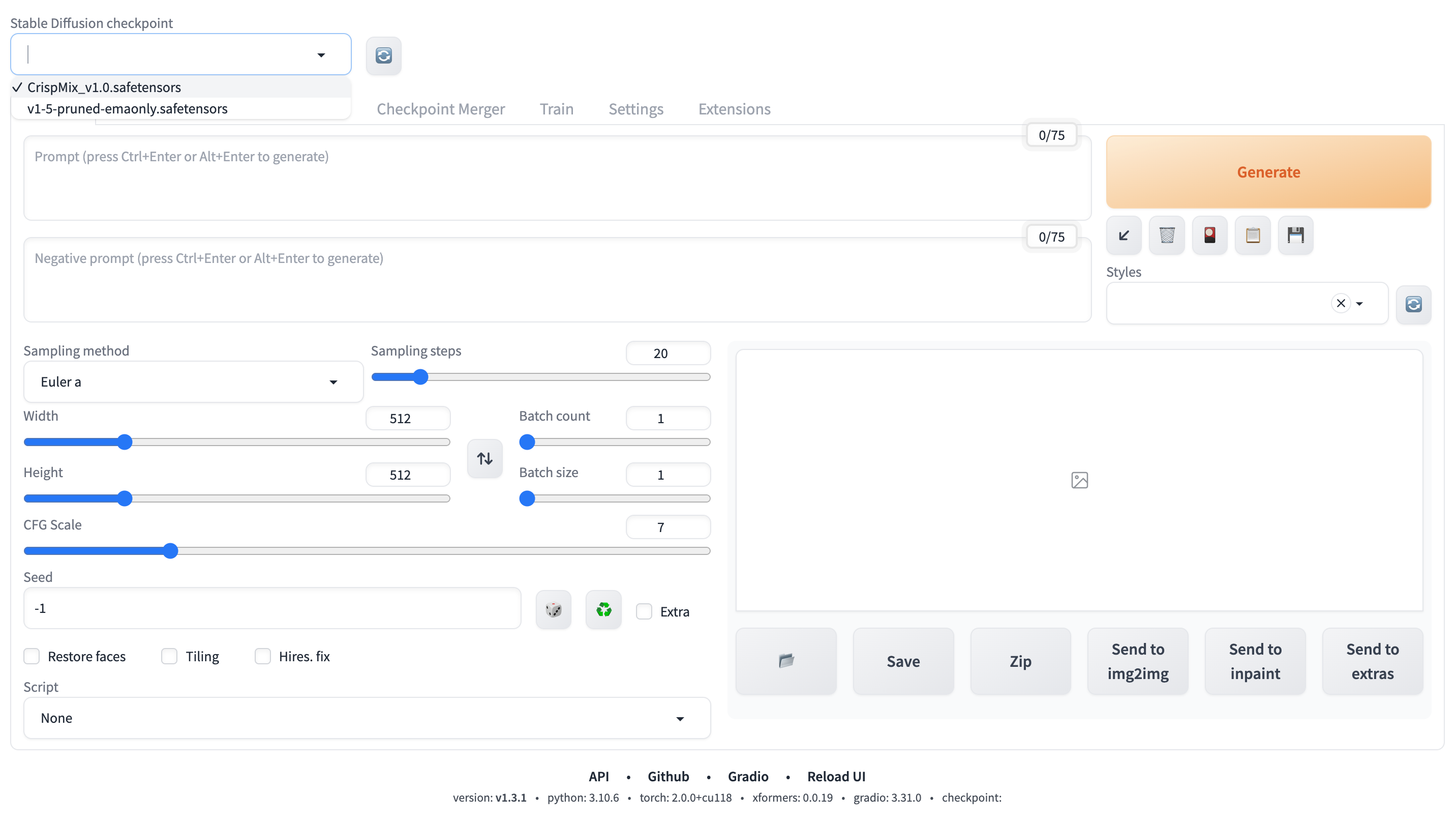
我们在左上角的 Stable Diffusion checkpoint 的下拉框看到已经有 明快 CrispMix 这个 Checkpoint 模型了,我们选择加载使用它。如图:
我们接着来用这个主模型画一下图看看效果是不是符合预期。我们输入提示词、负向提示词,并调整了相关参数后,生成了一张图片。如图:
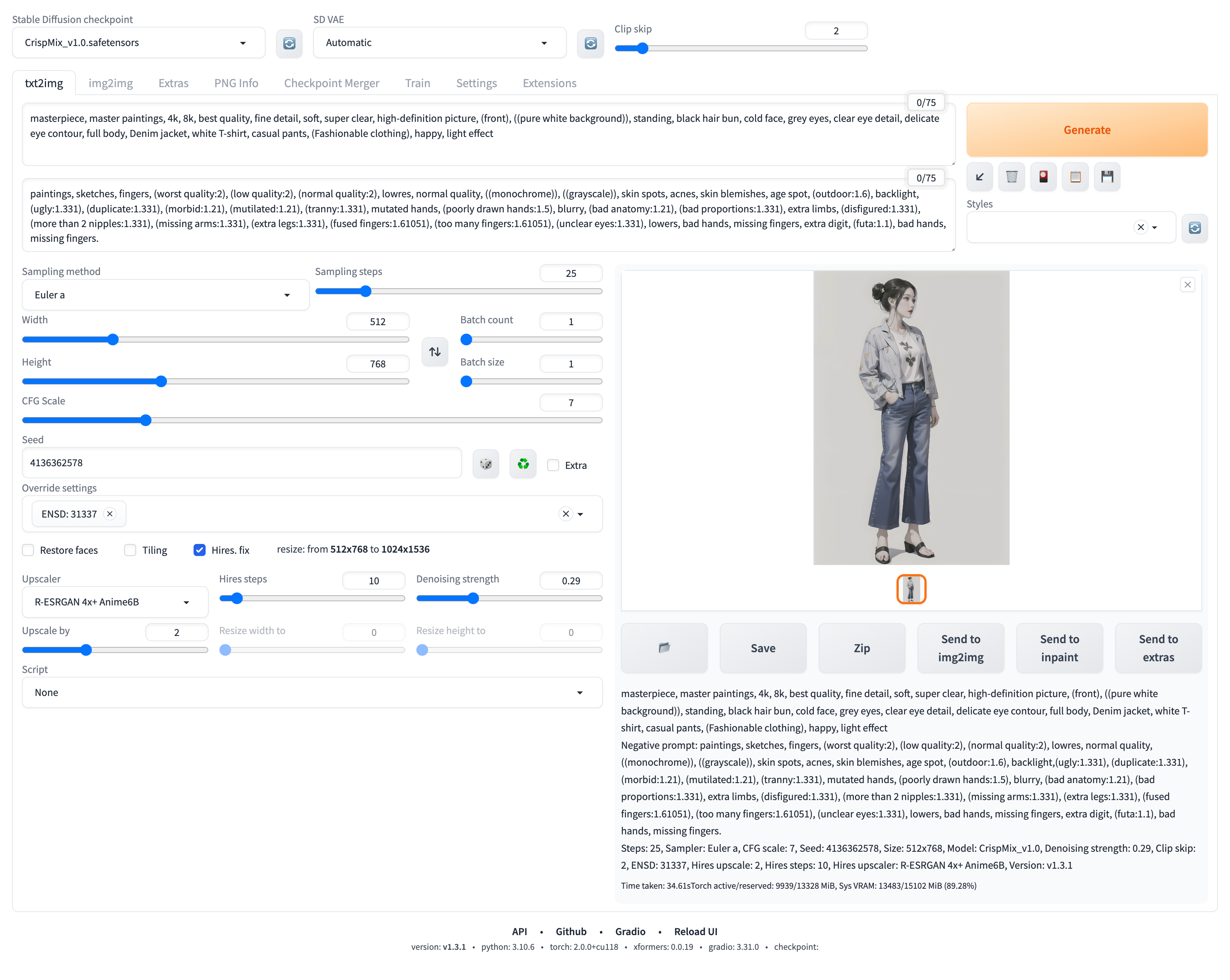
可以看到这里的图片有点暗:

这个色彩问题通常是因为我们选择的主模型需要额外的 VAE 模型来辅助调整生成图片的色彩饱和度。
3)模型配置:配置 VAE 模型并测试模型效果
我们接下来,介绍一下如何配置 VAE 模型。
不过,在这之前我们先来配置展示一下选择 VAE 模型的下拉框,如下图:
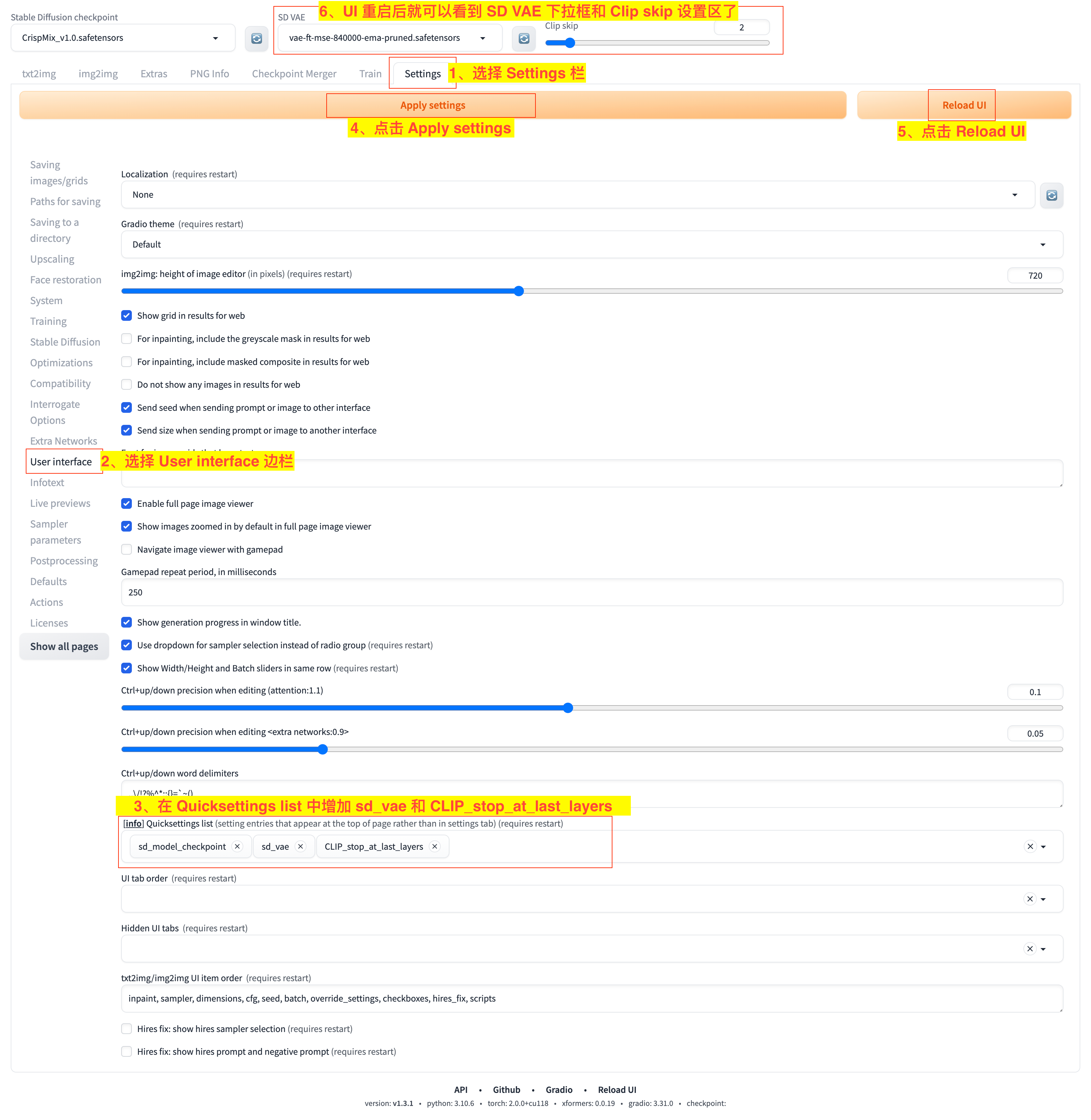
- 1)选择
Settings栏; - 2)选择
User interface边栏; - 3)在
Quicksettings list中添加sd_vae和CLIP_stop_at_last_layers选项; - 4)点击
Apply settings应用设置; - 5)点击
Reload UI重新加载 UI; - 6)等待 UI 重启后就可以看到
SD VAE下拉框和Clip skip设置区了。
接下来,我们通过链接 https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors 下载 vae-ft-mse-840000-ema-pruned 这个 VAE 模型文件。
下载完成后,我们将模型文件 vae-ft-mse-840000-ema-pruned.safetensors 拷贝到 stable-diffusion-webui/models/VAE 这个目录下。
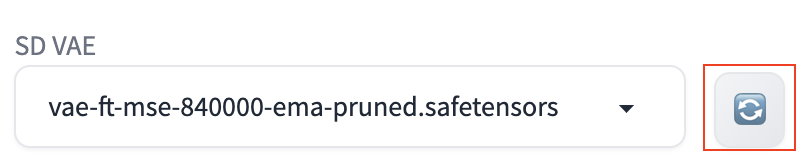
然后,我们就可以点击 SD VAE 下拉框右边的刷新按钮,并在 SD VAE 下拉框选择使用这个 VAE 模型了。如图:
接下来,我们再次使用同样的提示词和相关参数来重新执行上面的生成任务,如下图:
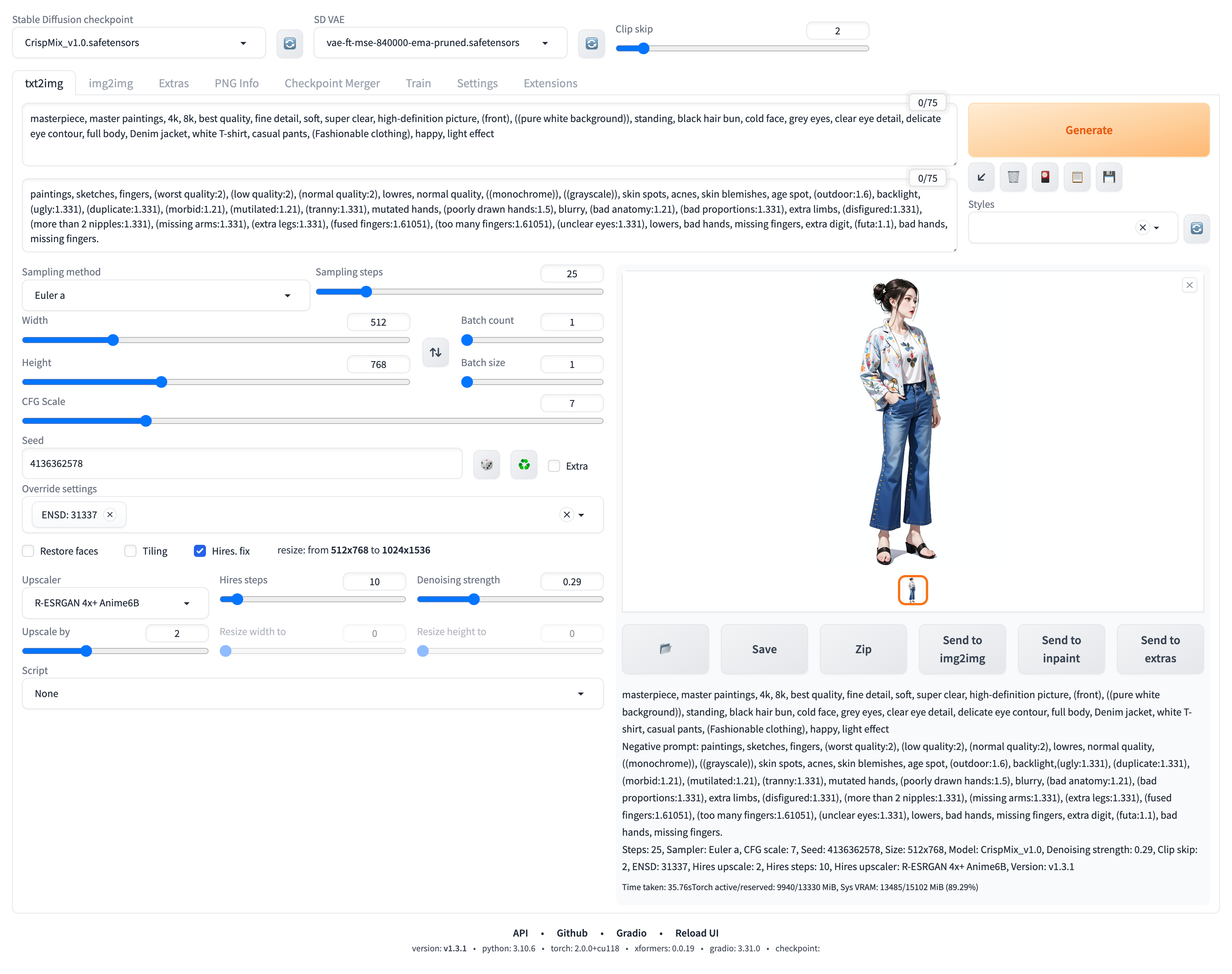
可以看到这次画出来的图像色彩明显鲜明饱和了许多:

4)模型配置:配置 LoRA 模型并测试模型效果
LoRA 是我们在使用 Stable Diffusion WebUI 时最常用的模型类型,我们接下来选择一个 LoRA 模型来介绍如何配置。如图:
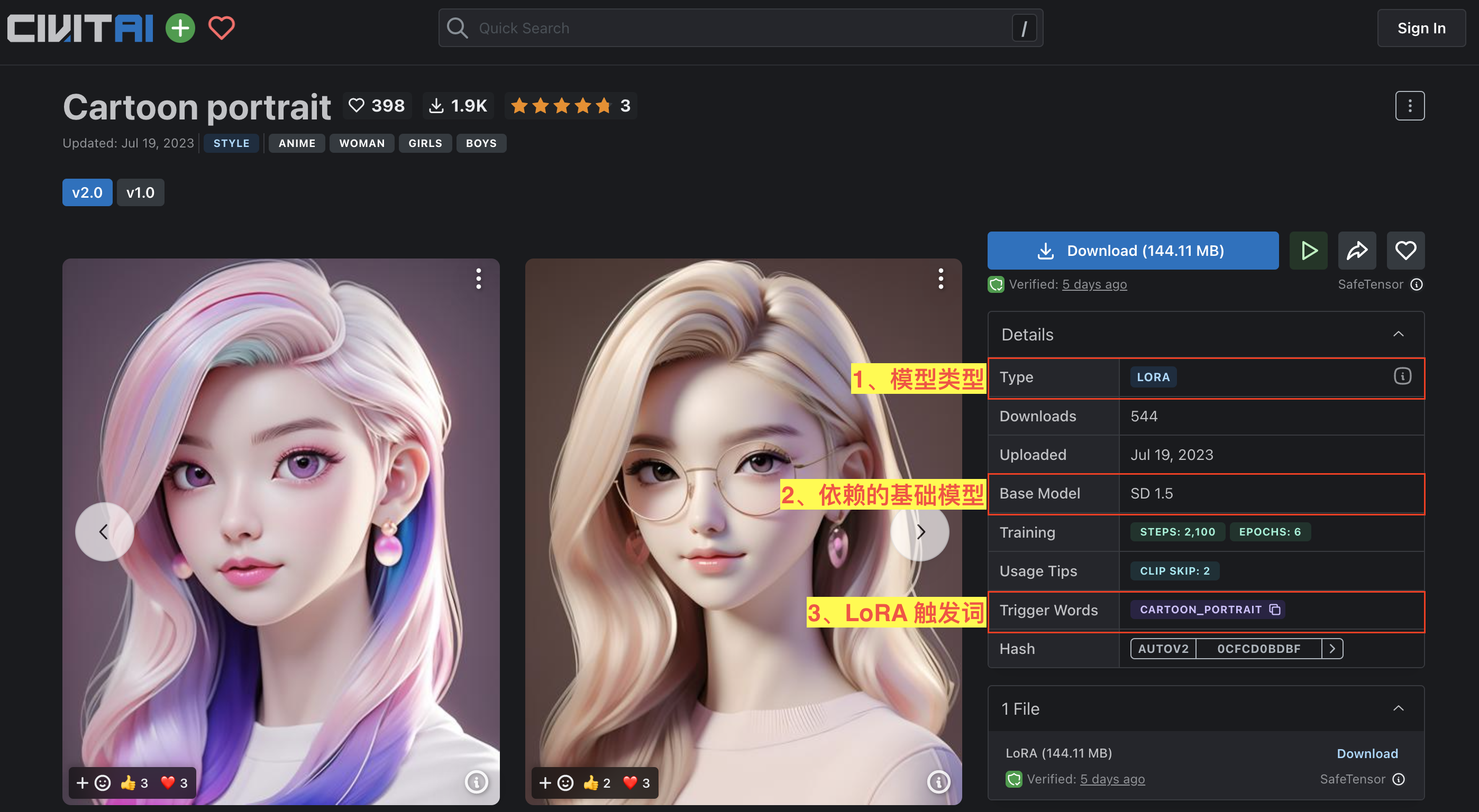
我们通过链接 https://civitai.com/api/download/models/120882 来下载 cartoon_portrait_v2.safetensors 这个用于画卡通头像的 LoRA 模型文件。
下载完成后,我们将模型文件 cartoon_portrait_v2.safetensors 拷贝到 stable-diffusion-webui/models/Lora 这个目录下。
然后,我们重启 Stable Diffusion WebUI 后,可以通过如图流程看到 LoRA 模型:
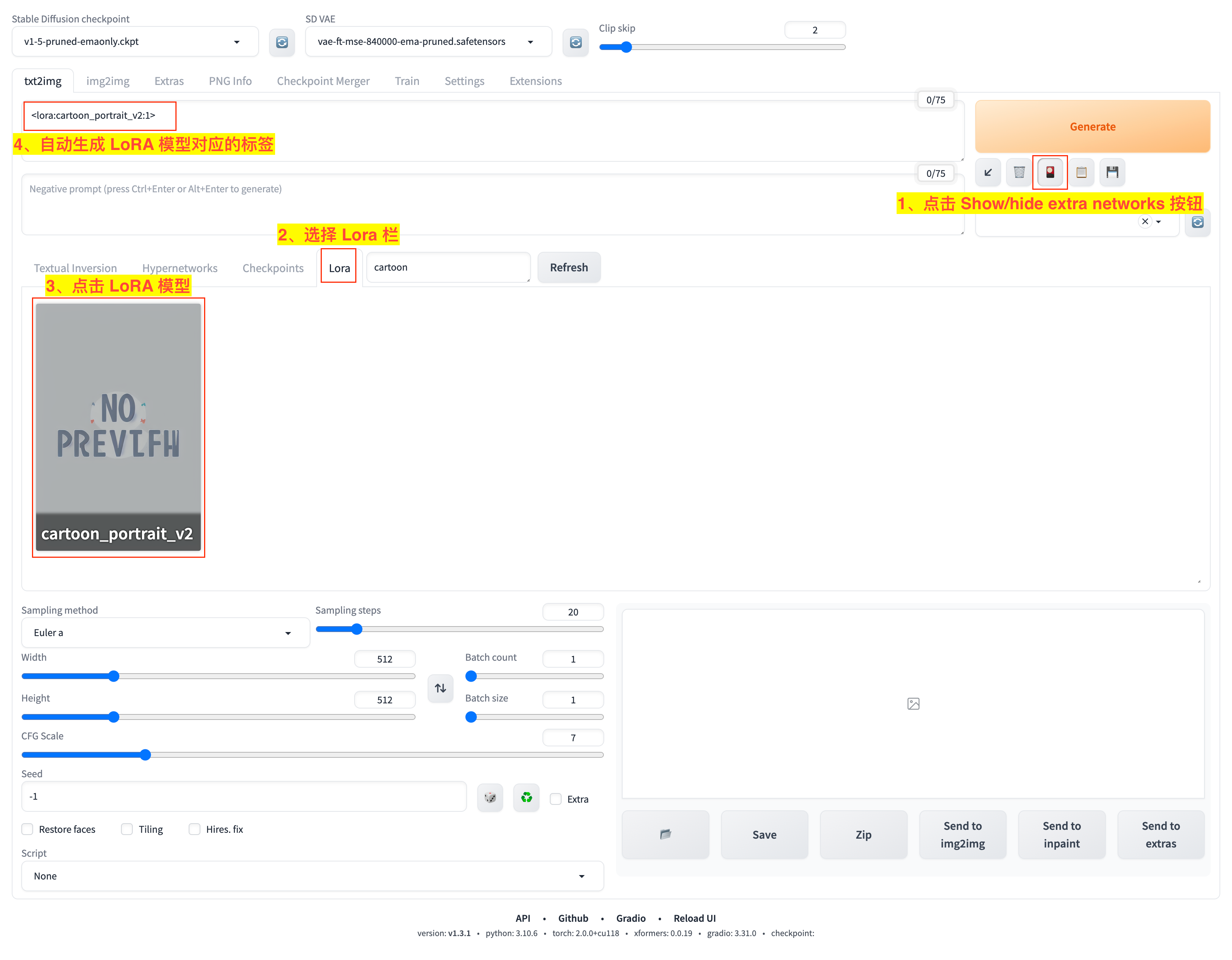
- 1)点击
Generate按钮下的Show/hide extra networks小按钮; - 2)在展开的
Extra Networks面板中选择LoRA栏,就可以看到cartoon_portrait_v2.safetensors模型了; - 3)点击 LoRA 模型;
- 4)可以看到在提示词输入框会自动添加模型对应的标签词
<lora:cartoon_portrait_v2:1.0>。
对于 LoRA 模型的使用有几点需要注意:
- LoRA 模型标签。我们上面提到的
<lora:cartoon_portrait_v2:1.0>是 LoRA 模型的标签,它遵循<lora:LORA-FILENAME:WEIGHT>这样的语法,LORA-FILENAME是你要用到的 LoRA 模型的文件名(不包含后缀名),WEIGHT则是设置模型的权重,具体设置多少一般需要参考模型发布者的介绍。比如<lora:cartoon_portrait_v2:1.0>就是对应我们要用到的cartoon_portrait_v2.safetensors模型,并设置权重为1.0。 - LoRA 模型触发词。有的 LoRA 模型需要一些特定的提示词来触发,比如我们用到的
cartoon_portrait_v2模型的触发词就是cartoon_portrait。这个在上面的模型介绍页面有标明Trigger Words。 - LoRA 模型需要与匹配的 Checkpoint 主模型一起使用。比如我们用到的
cartoon_portrait_v2模型可以和Stable Diffusion 1.5主模型一起使用。至于不同的 LoRA 模型需要搭配什么样的 Checkpoint 主模型,一般可以参考 LoRA 模型发布者的建议来选择。
我们在提示词里加上触发词、调整一下模型权重、完善其他描述:best quality, cartoon_portrait, 1girl, solo, long hair, looking at viewer, blonde hair, simple background, shirt, brown eyes, glasses, lips, round eyewear, lips, <lora:cartoon_portrait_v2:0.7>。
接下来,就可以生成图像来看看这个 LoRA 模型的效果了。如图:
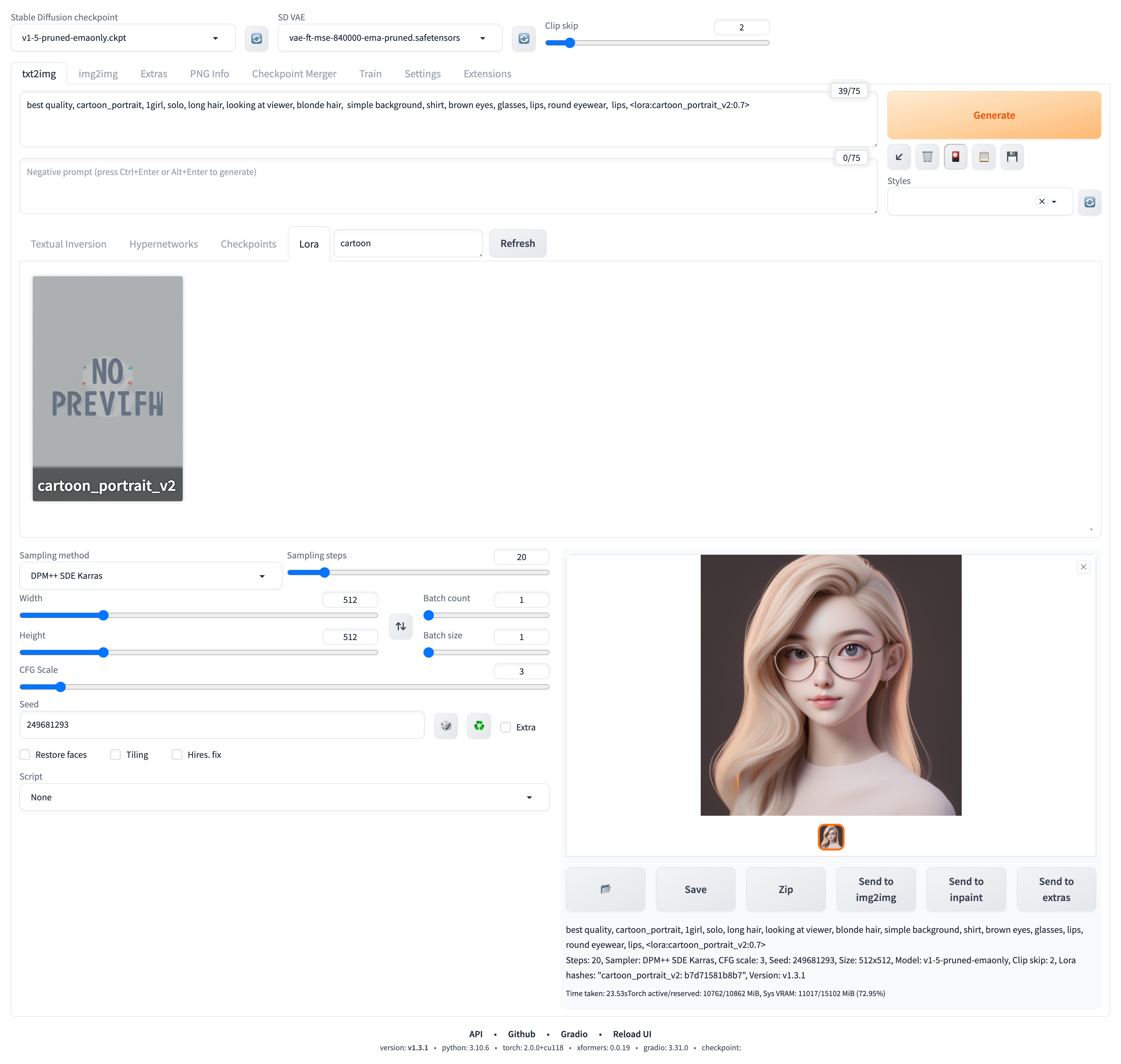
得到的生成结果如下:

3、常用的 Stable Diffusion 相关模型
1)Checkpoint 模型
| 模型 | 说明 | 地址 |
|---|---|---|
| Stable Diffusion 1.5 | Stable Diffusion 原模型 v1.5 | https://huggingface.co/runwayml/stable-diffusion-v1-5 |
| Anything | 二次元风格图像生成 | https://civitai.com/models/9409 |
| AbyssOrangeMix2 | 二次元风格图像生成 | https://civitai.com/models/4451/abyssorangemix2-hardcore |
| OrangeMixs | 二次元风格图像生成 | https://huggingface.co/WarriorMama777/OrangeMixs |
| Counterfeit | 高质量二次元人物和风景图像生成 | https://civitai.com/models/4468/counerfeit-v25 |
| MeinaMix | 高质量二次元风格人物图像生成 | https://civitai.com/models/7240/meinamix |
| ChilloutMix | 亚洲真人照片风格图像生成 | https://civitai.com/models/6424/chilloutmix |
| Deliberate | 欧美真人照片风格图像生成 | https://civitai.com/models/4823/deliberate |
| DreamShaper | 写实、原画等多种风格的人像和风景图像生成 | https://civitai.com/models/4384/dreamshaper |
| Lyriel | 支持多种风格的人物和风景图像生成 | https://civitai.com/models/22922/lyriel |
| Protogen | 支持多种风格的人物和风景图像生成 | https://civitai.com/models/3666/protgenx34-photoreaism-offiial-release |
| Dreamlike diffusion | 插画风格图像生成 | https://civitai.com/models/1274/drealike-diffsion-10 |
| Dreamlike photoreal | 真实风格图像生成 | https://civitai.com/models/3811/drealike-photreal-20 |
| Realistic vision | 真实世界风格的任务和环境图像生成 | https://civitai.com/models/4201/reaistic-ision-v20 |
| DDicon | B 端风格元素图像生成,配合 DDICON_lora 的 LoRA 模型使用 | https://civitai.com/models/38511/ddicon |
| Product Design | 工业产品设计相关图像生成 | https://civitai.com/models/23893/product-design-minimalism-eddiemauro |
| Isometric Future | 等距微缩风格图像生成 | https://civitai.com/models/10063/isometric-future |
| Vectorartz Diffusion | 等距微缩风格图像生成 | https://civitai.com/models/10063/isometric-future |
| Isometric Future | 矢量风格图像生成 | https://civitai.com/model/95/vectorartz-diffusion |
| Samdoesarts Ultmerge | Samdoesarts 艺术风格图像生成 | https://civitai.com/model/68/samdoesarts-ultmerge |
| Flonix MJ Style | Flonix MJ 插画风格图像生成 | https://civitai.com/models/6488/flonix-mj-style |
| architectural design sketches with markers | 建筑设计草图风格图像生成 | https://civitai.com/models/34384/architectural-design-sketches-with-markers |
| XSarchitectral-InteriorDesign-ForXSLora | 室内设计风格图像生成 | https://civitai.com/models/28112/xsarchitectural-interiordesign-forxslora |
| ReV Animated | 动漫人物或场景的 2.5D 或 3D 图像生成 | https://civitai.com/models/7371 |
2)LoRA 模型
| 模型 | 说明 | 地址 | 推荐搭配主模型 |
|---|---|---|---|
| KoreanDollLikeness | 韩国真人照片风格 | https://huggingface.co/Kanbara/doll-likeness-series/tree/main | ChilloutMix:https://civitai.com/models/6424/chilloutmix |
| JapaneseDollLikeness | 日本真人照片风格 | https://huggingface.co/Kanbara/doll-likeness-series/tree/main | ChilloutMix:https://civitai.com/models/6424/chilloutmix |
| ThaiDollLikeness | 泰国真人照片风格 | https://huggingface.co/Kanbara/doll-likeness-series/tree/main | ChilloutMix:https://civitai.com/models/6424/chilloutmix |
| 墨心 | 水墨画风格 | https://civitai.com/models/12597?modelVersionId=14856 | ChilloutMix:https://civitai.com/models/6424/chilloutmix |
| Gacha splash LORA | 带背景的立绘风格 | https://civitai.com/models/13090/gacha-splash-lora | - |
| 沁彩 Colorwater | 水彩风格 | https://civitai.com/models/16055/colorwater | - |
| blindbox | 盲盒娃娃风格 | https://civitai.com/models/25995/blindbox | RevAnimated:https://civitai.com/models/7371/rev-animated |
| DDicon_lora | B 端元素风格 | https://civitai.com/models/38558/ddiconlora | DDicon:https://civitai.com/models/38511/ddicon |
| Freljord | 场景风格 | https://civitai.com/models/20747/freljordt | - |
| 剪纸 | 剪纸风格 | https://civitai.com/models/14892 | - |
| Anime Lineart | 线稿画风格 | https://civitai.com/models/16014/anime-lineart-style | Anything V4.5:https://civitai.com/models/9409 |
| Concept Scenery Scene | 风景场景风格 | https://civitai.com/models/23682/conceptsceneryscenev2 | Counterfeit V2.5:https://civitai.com/models/4468/counerfeit-v25 |
| Howls Moving Castle | 哈尔移动城堡风格 | https://civitai.com/models/14605 | - |
| Makoto Shinkai | 新海诚风格 | https://civitai.com/models/10626/makoto-shinkai-substyles-style-lora | - |
| Studio Ghibli Style | 吉卜力风格 | https://civitai.com/models/6526/studio-ghibli-style-lora | Anything v4.5:https://civitai.com/models/9409 / AbyssOrangeMix2:https://civitai.com/models/4451/abyssorangemix2-hardcore |
| Airconditioner | 城镇、荒野等风景场景风格 | https://civitai.com/models/22607?modelVersionId=27334 | - |
| Stamp_v1 | 图标 Logo 风格 | https://civitai.com/models/15629/stampv1 | - |
3)VAE 模型
| 模型 | 说明 | 地址 |
|---|---|---|
| vae-ft-ema-560000-ema-pruned | Stability AI 官方发布的 VAE,适用大部分场景 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/blob/main/vae-ft-ema-560000-ema-pruned.ckpt |
| vae-ft-mse-840000-ema-pruned | Stability AI 官方发布的 VAE,适用大部分场景 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.ckpt |
| kl-f8-anime2 | 适用于二次元动漫场景 | https://civitai.com/models/23906 |
| Grapefruit VAE | 适用于二次元动漫场景 | https://civitai.com/models/27985 |
以上是常用的一些 Checkpoint 模型、LoRA 模型 和 VAE 模型 的示例,更多、更丰富的模型可以到上面我们介绍的模型发现和下载站点自行发现和查找。